Retour sur la Devoxx FR 2016

Du 20 au 22 Avril 2016 se tenait au Palais des Congrès la Devoxx France, regroupant plus de 2700 personnes pour 230 conférences.
Voici donc un petit retour sur l'état de la plus grosse conférence pour les développeurs Java et les tendances actuelles autour de la JVM.
La Devoxx
Cette année encore, la Devoxx comportait plusieurs formats de présentation :
- Les Universités, conférences de 3 heures permettant l'exploration en profondeur des sujets présentés et qui se déroulaient uniquement le Mercredi.
- Les Hands-on, workshops de 3 heures.
- Les Conférences, conférences classiques de 45 minutes.
- Les Tools-in-Action, sessions courtes de 25 minutes faites pour présenter un outil, une pratique ou une solution..
- Les Quickies, sessions de 15 minutes
Contrairement aux années précédentes par contre, la Devoxx a présenté cette année 2 séances de Keynotes les Jeudi et Vendredi matin au lieu d'une seule, choix que j'ai beaucoup entendu critiqué et que je regrette un peu moi-même, la qualité des Keynotes étant moindre qu'à l'édition précédente.
A côté des conférences se tenait également le salon Devoxx, non-accessible au public cette année. Parmi ce salon se trouvaient les "grands" comme RedHat et StackOverflow, un bon tiers de SSII, mais également des startups réunies au sein du "Village des startups" comme CleverCloud, MailJet et Alibeez.
Les conférences
Honnêtement, j'ai des sentiments plutôt mixtes quant aux conférences. Plusieurs m'ont beaucoup plu mais certaines étaient vraiment décevantes, le contenu étant d'un niveau moins avancé que ce à quoi je m'attendais ou que ce qu'il pouvait y avoir à la Devoxx Belgium.
De plus, l'idée de faire un workshop de 3 heures dans une salle ne comptant que 5 prises électriques pour 50 personnes n'était pas vraiment bien réfléchie...
J'ai donc pris le parti pris de vous faire un résumé des conférences qui m'ont plu :
Feign(ant) in Action - Igor Laborie
Avec la montée en puissance des applications Web et des architectures micro-services, vient la montée en puissance des services REST, presque devenus le standard de communications Web.
Il est donc normal que de nombreuses personnes tentent de simplifier l'implémentation de ces services, par la création de librairies ou de standards d'implémentation.
Igor Laborie intervient pour sa part dans le premier cas, en nous présentant la librairie Feign créée par Netflix, pionniers dans l'implémentation d'architectures micro-services.
Feign, donc, est une librairie Java permettant de simplifier la création de clients REST.
Le principe est simple : plutôt que d'implémenter complètement l'appel et le parsing de la réponse, on décrit juste dans une interface Java les extrémités du service REST que l'on souhaite interroger, ainsi que des encodeurs et décodeurs permettant de sérialiser la requête et désérialiser la réponse à la création du client.
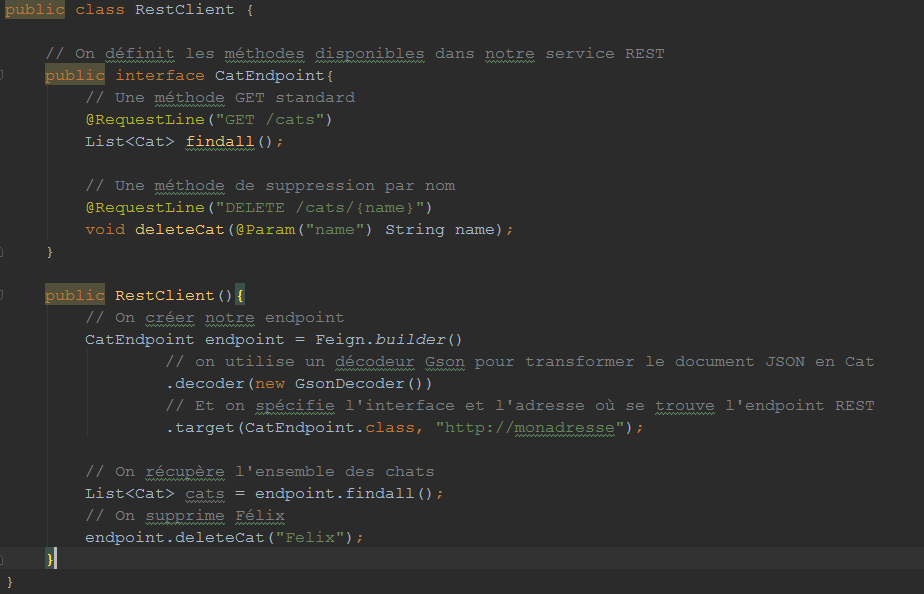
Un exemple d'utilisation de Feign
Dans cet exemple, nous avons utilisé un décodeur fournit par Feign mais il est apparemment très simple d'écrire ses propres encodeurs et décodeurs.
A première vue, cela simplifie donc grandement le code, peut-être pas en terme de complexité puisque écrire un client REST en soi n'est pas vraiment compliqué, mais en terme de lisibilité.
Reste à voir dans la pratique si des situations plus compliquées ne poseraient pas des problèmes à Feign
Pourquoi Maurice ne doit surtout pas coder en go- Jean-Laurent de Morlhon (Docker)
Durant cette conférence, Jean-Laurent nous présente son expérience avec le langage de programmation Go.
Il commence par nous expliquer les raisons pour lesquelles Docker a choisi Go comme langage pour l'ensemble de ses binaires :
- Compilation statique, pas de runtime à installer comme le JRE
- Les opinions sur Go sont plutôt neutres par rapport aux autres langages
- Bas niveau, parfait pour interagir avec le système d'exploitation
Malgré cela, si ils avaient démarré Docker aujourd'hui, ils l'auraient probablement démarré en Rust plutôt qu'en Go. Je suppose notamment pour des questions de performances, mais c'est principalement pour indiquer que le monde des langages change constamment et que le choix de Go chez Docker était aussi fortement lié aux tendances du moment.
Il continue par nous présenter Go dans son ensemble, dont voici quelques points que j'ai retenus :
- L'exécutable peut être généré pour n'importe quel environnement
- Il n'y a pas d'exceptions en Go, les exceptions sont des chaînes de caractères qui seront vides dans le cas d'un succès
- Go est très standardisé et dispose d'un auto-formatage forcé et un peu trop strict
- L'outillage de Go est très rustique
- Go est simple et verbeux, facile à relire mais avec beaucoup de répétition
- Go n'est pas simple à tester et tester du legacy-code est tout simplement horrible
En résumé et ce que je retiens de cette conférence est que Go est un langage comme les autres, qui dispose de ses avantages et de ses inconvénients. J'étudierai probablement son utilisation pour faire du bas niveau (avec de l'interaction système) mais pas pour d'autres utilisations.
Analyzing Images with Google's Cloud Vision API - Sara Robinson (Google)
Dans ce Quickie, Sara Robinson nous présente succinctement les API Google Vision et Google Speech.
L'API Google Vision permet l'analyse d'image sous plusieurs formes :
- Reconnaissance de visage
- Un ou plusieurs visages parmi l'image
- Détection de la position des yeux, du nez et de la bouche
- Détecte l'émotion sur le visage
- Détection d'entité
- d'objets communs comme des fruits ou autres
- de lieux/monuments
- L'extraction de texte
- Génération de mots-clés liés à l'image
Un exemple de réponse lors de l'analyse de texte de l'image Google
L'API Google Speech quant à elle permet l'analyse et la retranscription d'audio :
- Gère plus de 80 langues
- Permet de filtrer le contenu inapproprié
- Permet de transcrire du texte en audio
- Permet de traduire de l'audio en texte ou audio d'une langue à une autre
Derrière ces deux API, tournent des algorithmes de Machine Learning dont la complexité est complètement masquée par les services REST exposant leurs fonctionnalités.
Plusieurs librairies sont également fournies par Google dans les langages python, C# et Java, permettant de faciliter les interactions avec les API REST.
En conclusion, bien que la présentation ait été courte (format oblige), Sara m'a bien donné envie de tester ces API afin de bien comprendre ce dont elles sont capables, ce qui pourrait nous donner de nouvelles idées pour les hackathons.
Containers, VMs... Comment ces technologies fonctionnent et comment les différencier - Quentin Adam (Clever Cloud)
Il y a apparemment quelque chose qui énerve profondément Quentin Adam, le CEO de Clever Cloud, et c'est apparemment qu'on lui dise que "les containers, c'est un peu comme les VMs donc c'est secure".
Il profite donc de ces 45 minutes qu'il a pour nous expliquer un peu l'historique des containers et pourquoi décidément non, les containers ne sont pas du tout la même chose que les machine virtuelles.
Il commence par nous présenter que les premiers containers se reposaient sur l'isolation du système de fichier grâce à chroot, qui permet de changer le répertoire racine apparent et ainsi créer ce qu'on appelle une chroot jail (le terme jailbreak vient de là). Pour infos, la version 4.0 de chroot introduisant les "jail" a été introduite en 2000, et Docker n'est donc pas le premier outil à permettre la containérisation.
Vient ensuite en 2008 la notion de cgroups, qui permet d'isoler l'utilisation des ressources d'une machine pour un ou plusieurs processus du système (CPU, mémoire, I/O disque, etc...) et c'est là qu'intervient Docker qui s'est surtout démarqué de ses concurrents en proposant sa solution au bon moment et de la bonne manière.
Mais donc voilà, les containers tel qu'on en entend parler actuellement ne sont rien de plus que des processus isolés par un contexte de répertoire et des permissions sur les ressources, ces ressources restant partagées avec l'ensemble des containers de l'environnement.
Il est donc complexe de surveiller et de sécuriser l'utilisation des ressources utilisées par ces-dits processus.
Quentin nous montre également par l'exemple qu'il est possible via une Fork Bomb exécutée dans un des containers, de faire crasher le système complet et donc l'ensemble des containers tournant sur la machine.
De leur côté, les machines virtuelles sont de vraies boîtes noires permettant une allocation fixe des ressources et n'ayant absolument aucun accès au système les hébergeant. De plus, les performances des VMs ne sont pas bien différentes des containers puisque le vrai problème reste et restera probablement au niveau des écritures et lectures disque, et que les containers n'apportent aucun avantage de ce côté. Pour les critiques qui diront que les VMs mettent trop de temps à démarrer puisqu'elles doivent démarrer un OS contrairement aux containers, Quentin Adam nous explique que chez Clever Cloud, leurs machines virtuelles démarrent en seulement quelques secondes et qu'il ne s'agit donc que de paramétrer correctement sa machine virtuelle.
Enfin, Quentin émet quelques réserves quant à l'utilisation de la distribution Alpine par quelques containers, dont Docker, qui a coupé au couteau et ré-implémenté quelques librairies coeur de Linux, perdant ainsi l'ensemble de l'historique et du travail communautaire, dé-sécurisant grandement la distribution.
Cette conférence finie, je comprends mieux le scepticisme que portent les administrateurs systèmes et réseaux à cette vague de Hype que sont les containers.
Mais il faut aussi rappeler que, bien que les containers soient moins sécurisés que les machines virtuelles, ils sont également plus simples à créer, configurer et déployer, et que le problème de la sécurité est la première des priorités des gestionnaires de containers et donc qu'on peut imaginer voir arriver d'ici assez peu de temps des solutions plus sécurisées.
100% Stateless avec JWT - Hubert Sablonnière (INEAT Conseil)
Au sein de l'amphitéâtre et à l'occasion de sa conférence, Hubert Sablonnière nous a présenté le pourquoi et le comment des JSON Web Tokens, une solution alternative aux cookies et aux cache distribués pour l'identification de l'utilisateur et le partage de ses données session.
Il a commencé par nous rappeler les autres solutions disponibles et leurs problèmes. Par les cookies, la solution la plus simple pour identifier une session utilisateur mais qui pose de gros problèmes de sécurité et de scaling (la session doit être partagée par tous les serveurs).
Il continue avec le cache partagé qui ramène l'ensemble des caches sur un seul point d'entrée, ce qui peut poser des problèmes quand ce dernier crash, pour développer sur le cache distribué qui permet de répliquer le cache sur l'ensemble des machines plutôt que sur un seul point d'entrée afin d'éviter le SPOF (Single Point Of Failure).
Mais le problème avec le cache distribué se trouve dans son utilisation au quotidien, vu qu'il est souvent difficile à administrer sur de grosses architectures.
Vient donc JWT, une solution alternative à l'ensemble de ces solutions.
JWT est un token par valeur, c'est à dire que lire ce token nous donne l'ensemble des informations, contrairement aux tokens par référence qui permettent juste d'accéder aux informations via un service tierce en utilisant la référence portée par le token.
JWT donc, est un token par valeur composé d'un Header, d'un Payload et d'une Signature, chacun encodé en Base64 nous donnant un token de la forme :H34D3R.P4YL04D.S1GN4TUR3
Le Header décodé est un document JSON décrivant l'algorithme de cryptage utilisé.
Le Payload décodé quant à lui est un document JSON contenant des informations liées au token ou les données sessions à utiliser lors des échanges.
Enfin, la Signature correspond au résultat du cryptage du Header encodé et du Payload encodé à l'aide d'un secret partagé.
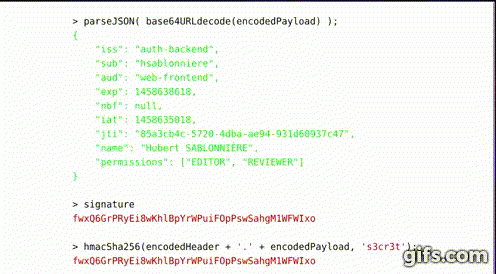
Un exemple démontrant comment modifier le contenu modifie la signature
Le client et le serveur peuvent donc tous les deux, à l'aide du secret partagé, vérifier la validité du token JWT en recréant la signature et en vérifiant que la signature du token récupéré est la même que celle qu'ils ont récupéré. Difficile donc de modifier le contenu du token entre le serveur et le client sans que la machine recevant le token sans aperçoive (voir Gif).
Cela permet donc d'avoir des échanges Stateless, sans rien garder en session.
Reste à vous de décider la manière dont vous partagés le secret utilisé pour crypter votre signature...
Dashing deux en un, pour un dashboard étincelant - Nathaniel Richand (AgileTribu)
Nathaniel Richand nous a introduit pendant 30 minutes à l'outil Dashing.
Dashing est un outil permettant de créer facilement des Dashboard, en agençant un ensemble de widgets développés en HTML, coffeeScript et scss, que vous allez brancher à vos données via des jobs écrits en Ruby.
A première vue, Dashing me semble très facile d'utilisation et même créer ses propres widgets et de les intégrer à ses propres dashboards semble très simple. Très probablement un outil que j'utiliserais par la suite.
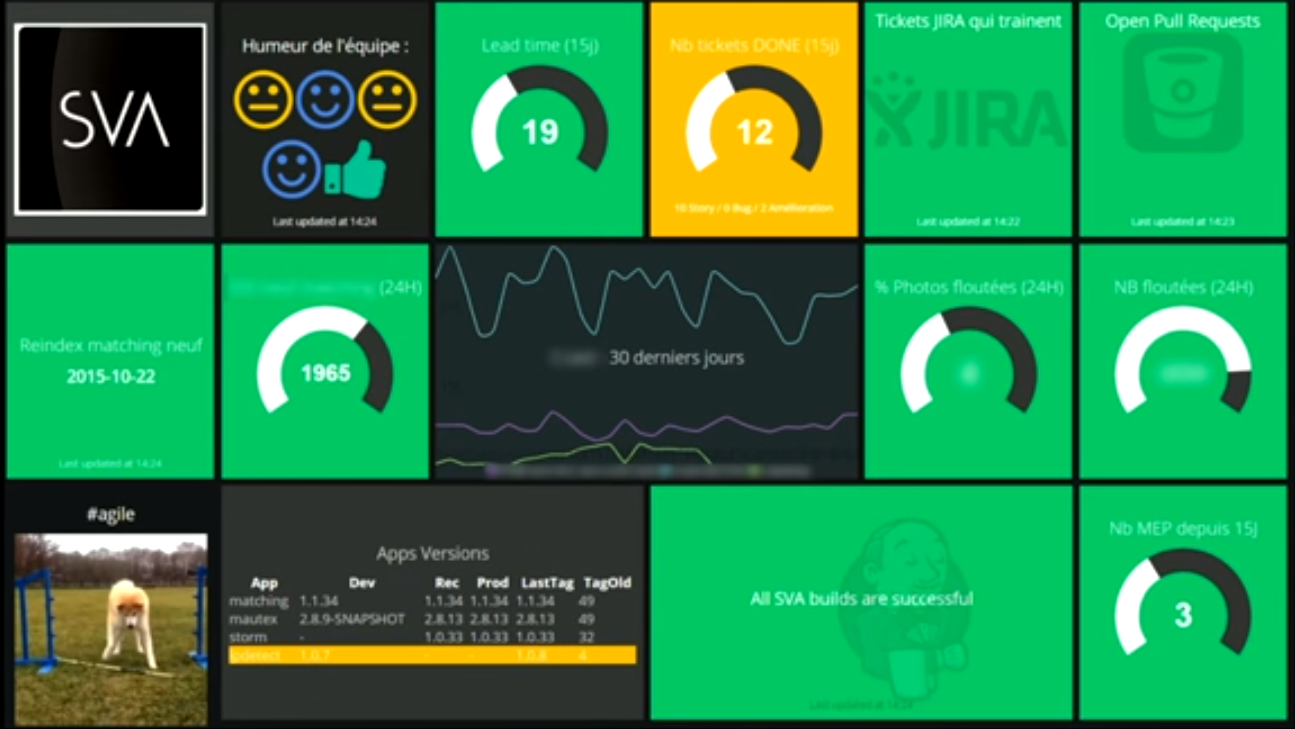
Un exemple de Dasboard Dashing


