All Your Base 2015 partie 2 : Conférences de l'après-midi

Il semblerait que nos voisins Anglais, fiers inventeurs du sandwich triangle, tiennent particulièrement à cette coquetterie gastronomique. Nous n'y coupâmes donc pas, puisque le pain le fût. Après donc un lunch bag so local pris sur le pouce au milieu du jardin intérieur du Barbican Centre, on reprend le rythme pour quatre autres conférences.

On a fait pire, comme cantine.
Conférences de l'après-midi
14h00 : Do what matters, not what's shiny and new
Par Brian Scalan
L'intitulé touche un point sensible de notre métier. En effet, par enthousiasme nous avons parfois tendance à passer plus de temps sur des nouveautés attractives que sur des tâches rébarbatives qui pourraient pourtant se révéler plus profitable. C'est ce qu'à voulu partager avec nous Brian Scalan au travers de l'exemple d'un projet de changement d'hébergement pour les bases MongoDB d'Intercom. Dans une première partie il nous explique le gain attendu, des économies et une meilleure sécurité. Il nous rappelle par ailleurs assez justement à quel point une faille de sécurité rendue publique peut créer un déficit de réputation bien plus grave qu'une perte financière. Ensuite les différentes étapes du projet nous sont expliquées, et enfin le résultat obtenu finalement conforme aux attentes initiales. Brian nous indique entre autre que cette migration, sans aucune nouveauté implémentée, a fait économiser plus de 60% du budget auparavant alloué à l'hébergement de leurs bases MongoDB.
L'auteur applique sa philosophie à fond. L'important c'est d'avoir des slides, pas qu'ils brillent de partout.Voir l'image sur Twitter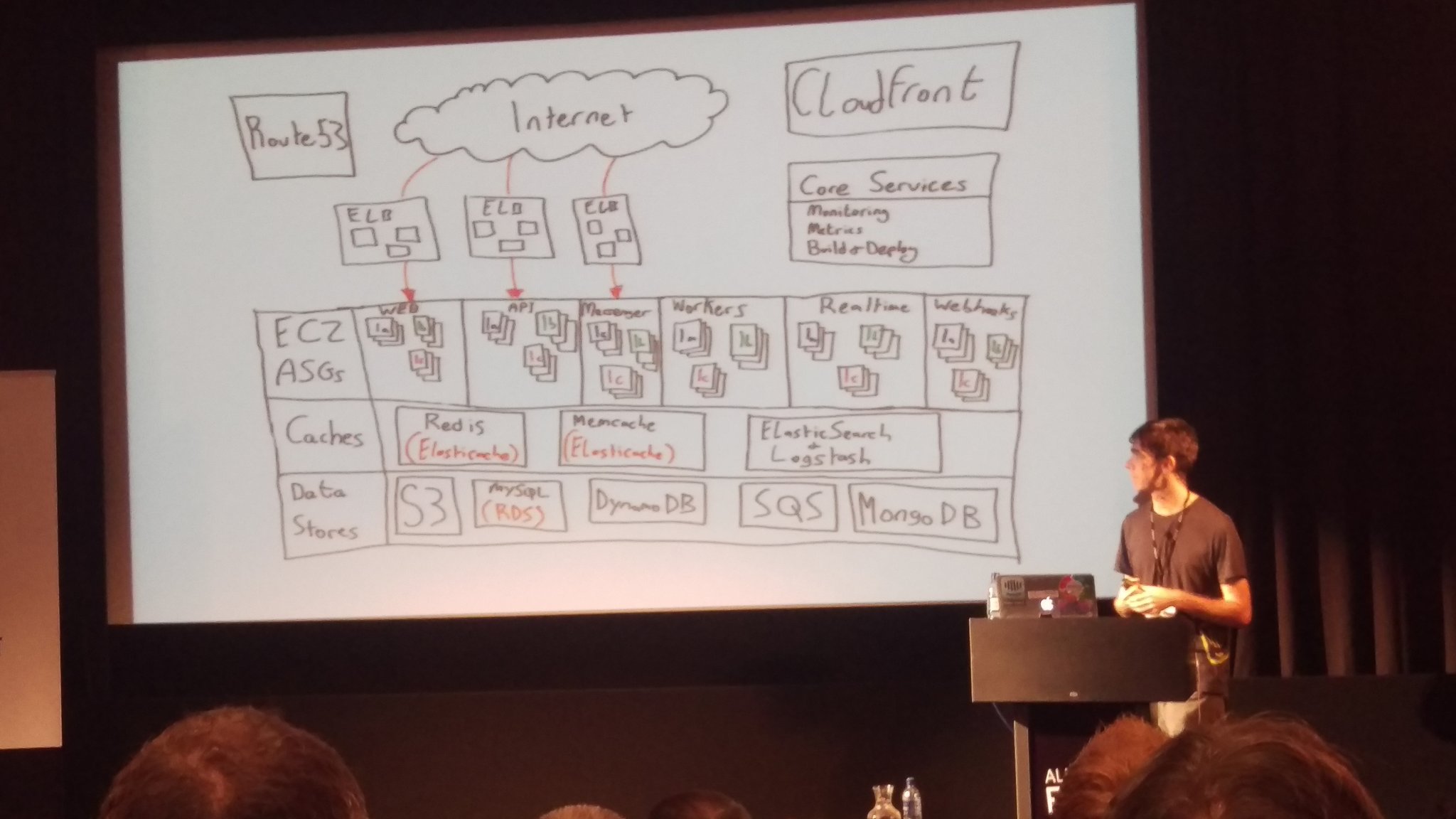
SuivreRussell Heilling @xchewtoyx I find presentations with no theme and hand drawn diagrams are much more intimate. #aybconf
15:06 - 13 Nov 2015
Soyons honnête : préparer une présentation voulue intéressante alors que la moitié consistera à décrire étape par étape un projet qu'on qualifie soit même de "pas rutilant ni nouveau", c'était déjà un exercice périlleux. Qui plus est, n'étant pas du tout familier de MongoDB j'ai vite été perdu pendant la présentation. Mais surtout j'ai l'impression qu'on est passé à coté du sujet. En effet, Brian commence, mais également conclue sur le fait que l'important au final c'est le gain apporté par le projet, pas qu'ils soit passionnant d'un point de vue technologique. Soit, cependant je crois qu'on appelle ça un ROI, et que ça fait un moment que la plupart des entreprises (en tout cas celles qui survivent) ont saisi le concept, et par contre il n'aborde pas du tout les limites de cette approche. D'abord, dans l'exemple donné l'évaluation du gain financier est évidente: ça revient très grossièrement à faire un la différence entre les tarifs des deux solutions à service égal. On se lance dans un projet ennuyeux mais avec une très bonne idée de ce qu'on va y gagner. Quand on introduit une nouveauté, ça tient bien plus de l'hypothétique : Il faut tester, étudier le résultats chez d'autres utilisateurs, prévoir les éventuels nouveaux usages qui découle des nouvelles fonctionnalités, toute sorte de choses coûteuses dont on n'aime pas entendre parler à l'heure de fixer les budgets. De fait à vouloir se focaliser sur le gain immédiat uniquement, on prend le risque de freiner l'innovation, et donc de se retrouver avec un coût de maintenance prohibitif sur une application dépassée 10 ans après.
Mais surtout, cette façon de voir les choses pose un problème de management d'équipe. L'interêt du sujet est l'un des moteurs principaux de notre métier et de nombreux développeurs revendiquent de faire leur métier par passion. Dès lors, en priorisant systématiquement les projets les plus rémunérateurs mais égalements les plus rébarbatifs, un manager s'expose au risque de perdre ses meilleures ressources, attirées par des projets plus créatifs. Ces deux aspects passent complètement à la trappe dans la présentation. Trop "shiny and new", peut-être.
14h30 : PostgreSQL is YeSQL!
Par Dimitri Fontaine
Ouf, ENFIN!! Quelqu'un vient nous proposer un peu de SQL, je respire à nouveau. Une chose est sûre, Dimitri Fontaine n'est pas venu pour se laisser conter des histoires de Map-Reduce. Sa présentation est un peu l'anti Pattern de la journée, une étape nécessaire pour une assistance où les développeurs web peu habitués aux SGBDR sont très représentés. Mais une présentation qui a également mis une petite claque au développeur SQL chevronné que je suis.

Croyez le ou non, il y a eu des nouveautés depuis.
On commence par remettre les choses à leur place. C'est vrai qu'entre les WebScaleSql, les MongoDB et autres dont on nous parle depuis le début de la journée, on pourrait avoir tendance à penser que les bases de données relationnelles appartiennent au passé. Dimitri vient nous rappeller une chose importante : Les bases distribuées, c'est performant mais c'est aussi bien compliqué, et tout le monde n'a ni besoin du volume et de la distribution de la base utilisateurs de FaceBook, ni les problèmes de disponibilités d'Uber. En fait, en réalité, ça ne concerne que très peu de société, et pour toutes les autres, le choix d'une base relationnelle présente de sérieux avantages. Ils nous est rappelé le principe des propriétés ACID que respecte PostgreSQL et à quel point ça simplifie le maintien des données. Une autre point judicieux : il est possible aujourd'hui de trouver à tarif raisonnable des serveurs très puissant. Il peut être plus profitable d'acheter un serveur plus gros, plus qu'un autre identique pour créer un cluster.

Le message de Dimitri: "Scale up before you scale out"
Dimitri est ensuite revenu sur la possibilité de mettre en place un système de Haute Disponibilité avec PostgreSQL via une architecture Maître/Esclave, l'occasion de sortir quelques piques bien placées puisque cette architecture avait été sérieusement critiquée par Matt Ranney le matin même. Enfin nous avons eu une demonstration des possibilité de la couche SQL. D'abord un point intéressant pour les utilisateurs d'Oracle ou de MySQL, sous PostgreSQL le DDL est transactionnel, ce qui veut dire que vous pouvez faire un rollback sur un ordre DROP. Ceux qui ont déjà fait des scripts de livraisons relançables un peu compliqués doivent maintenant être au bord des larmes de ne pas avoir une telle possibilité. Ensuite nous avons vus quelques cas concrets, avec :
- des exemples classiques de fonctions fenêtrées, qui sont normalement familières aux développeurs Oracle aujourd'hui
- l'utilisation des operateurs d'overlapping. Concrètement lorsque vous avez des données de type intervalle de date, ou alors formes géométriques dans un repère, ces opérateurs vous indique si deux données se superposent, si l'une est incluse dans l'autre, etc...C'est extrêmement pratique. Imaginez juste le code que vous devriez taper dans la plupart des langages pour vérifier si deux périodes saisies se chevauchent. Ces opérateurs font ça en une ligne dans la clause WHERE.
- Enfin nous avons eu droit à quelques exemples de manipulations de zones géographiques et de formes géométriques en tant que type natifs, ainsi qu'à la présentation de types d'index, dont certains justement adaptés à ce type d'usage cartographique.
Au delà de présenter certaines fonctionnalités de PostgreSQL, Dimitri prend plaisir à nous indiquer que toutes ces possibilités n'ont rien de nouveautés, mettant ainsi en évidence le manque d'intérêt des développeurs pour le langage SQL.
Affable, Dimitri propose des points de repère temporels pour ceux qui n'étaient pas nés ne situeraient pas bien les normes SQL.
SuivreSimon /\/\e†s0|\| @drsm79 "'92 the year of IPv6 and Unicode" #aybconf #geekjokes
15:44 - 13 Nov 2015
L'example de l'overlapping est très judicieux : les problèmes de recouvrement de période sont assez récurrents dans des domaines comme l'évènementiel, les ressources humaines, l'e-commerce ou la finance, et sont plutôt complexes à traduire dans la plupart des langages. Pourtant dans l'assistance peu (pour ne pas dire personne) connaissaient ces opérateurs, et je ne les ai personnellement jamais vus utilisés dans aucun projet sur lesquels j'ai pu travailler (Les mêmes fonctionnalités existent dans Oracle 9i et plus mais avec une autre syntaxe. On parle donc d'une version sortie il y a 14 ans, quand même).
Ce qui ressort de la présentation de Dimitri selon moi, c'est que le SQL, bien qu'étant parmi les plus anciennes technologie encore massivement utilisées sur le marché de l'informatique, est réellement quelque chose de méconnu et sous exploité. D'un côté le monde du web est enclin a utiliser les technologies qui se sont développées avec eux, et de l'autre les projets développés autour d'un gros SGBDR se contente de capitaliser sur du code souvent vieux de plus d'une décennie sans jamais chercher à découvrir les nouvelles possibilités offertes à chaque mise à jour (le syndrome du "On a toujours fait comme ça"). Il est vraiment dommage que les acteurs les plus modernes du marché ne cherchent pas à se former dessus pour se simplifier la vie mais également pour populariser les nombreuses nouveautés apportées à chaque évolution de la norme.
Dans le cas plus particulier de PostgreSQL, je me rends compte après cette présentation que l'image du produit est très floue pour la plupart des développeurs SGBDR. Oui c'est une base relationnelle, c'est le truc Open Source, mais est-ce que c'est performant, quel est l'état du support SQL et PL/SQL, ... Je ne l'ai jamais utilisé en condition réelles (et j'ai hâte de m'y mettre), mais il est clair pour moi que sur le papier PostgreSQL rivalise avec les ténors du marché. Peut-être lui manque-t-il encore une meilleure démarche de communication pour obtenir une adoption plus massive et grignoter des parts de marché à Oracle et SQL Server sur le terrain de leurs clients les plus conservateurs, mais je n'y vois personnellement aucun obstacle technique.
Les slides de la présentation sont disponibles ici.
15h30 : Adventures in building your own database
Par Alex Scotti
Une autre conférence qui m'intéressait tout particulièrement, ne serait ce que pour savoir ce qui peut pousser une entreprise à développer son propre système de gestion de base de données. Alex Scotti est donc le créateur de Comdb2, SGBD utilisé chez Bloomberg. Ce point a assez vite été éclairci par Alex, puisque le besoin prioritaire était la Haute Disponibilité. On est donc sur une base de donnée orientée HA (High Availability) avant tout, et dont c'était au début l'unique fonctionnalité. Les premières versions sont Schema Less. Alex nous explique ensuite comment les fonctionnalités se sont ajoutées à l'usage en fonction des besoins mais aussi des difficultés rencontrées.
- Une couche d'abstraction SQL qu'il nous décrit comme indispensable. Venant de quelqu'un que j'ai entendu dire qu'il détestait le langage SQL quelques heures après, c'est quelque chose.
- Des fonctionnalités de HA qui découle de sa propre conception de la propriété durabilité (le D de ACID). Pour Alex Scotti, la Haute Disponibilité est indissociable de la durabilité dans le sens où c'est bien la peine d'avoir des données durablement écrite en base de données s'il n'est plus possible des les lire parce que le système est tombé.
- Le concept de Single System Image, il s'agit d'une couche d'abstraction qui permet de traiter la base comme étant unique alors qu'elle est en réalité distribuée. Comdb2 résoud ainsi les problématiques d'accès concurrents.
Comme disent les franglais : ça fait sens.
Suivre
16:50 - 13 Nov 2015
Au cours de sa présentation Alex soulève un point interessant concernant la fiabilité des SGBD. Ils peuvent devenir inaccessibles. Nous sommes habitués à cela, et intégrons la gestion d'erreurs à nos développement. Cependant nous n'accepterions pas d'utiliser un langage où les fonctionnalités basiques ne seraient pas fiable. Aucun développeur ne trouverait acceptable de mettre une gestion d'erreur et une méthode de calcul alternative sur une multiplication. Pour Alex, l'accès aux données et un autre type de fonction basique et ne devrait pas renvoyer d'erreur, ou plus précisément on ne devrait pas avoir besoin de prévoir des alternatives en cas de problème. C'est encore une fois liée à la HA. Si lorsque un gros problème réseau bloque une partie des noeuds, la base de donnée devient inaccessible, alors encore une fois on ne peut plus parler de Haute Disponibilité.
16h00 : Building a time series database: 10^12 rows and counting
Par James Blackburn
Pour la dernière conférence de la journée, James Blackburn nous présente son outil Artic, Une base de donnée orienté séries temporelle et ticks basé sur MongoDB et Python. Je ne vais pas forcément développer cette présentation car en plus d'être complexe techniquement et de contenir beaucoup de benchmarks, elle couvre un besoin fonctionnel très particulier.
C'est essentiel, la clarté du propos.
Suivre
17:09 - 13 Nov 2015 · City of London, London, United Kingdom
Ce que l'on peut en retenir toutefois (en dehors du fait qu'Artic est super rapide pour faire quelque chose qui ne sert qu'aux Hedge funds et à 2-3 labos de recherche) : James fait à un moment un benchmark comparatif Oracle / MongoDB sur une extraction de 10000 lignes, et en arrive à un résultat de 2,2s pour Oracle vs. 4ms pour Mongo. De quoi raviver la guerre entre SQL et NoSQL. Toutefois ici l'objectif de James et de sortir toutes les données le plus vite pour effectuer les calculs localement, avec Matlab. C'est juste absolument tout le contraire de ce pourquoi un SGBDR est conçu, et j'ai envie d'ajouter qu'un développeur chargé de faire du calcul analytique sur MongoDB va probablement bien s'amuser lui aussi. Ce que je veux dire par là c'est que James démontre bien qu'il y a deux types de produits distincts qui n'ont pas du tout les mêmes usages. On ne peut pas mettre en concurrence les bases SQL et NoSQL, elles peuvent même être complémentaires.
Fin de journée
La conférence c'est terminée sur une rapide séance de Questions/Réponses, une remise de cadeaux pour les concours organisés par les différents sponsors et un dernier échange autour d'un verre ou j'ai pu parfaire ma maîtrise de l'anglais en condition hostile (suivre une conversation en anglais est une chose, suivre un débat en anglais sur le SQL lancé après plusieurs bières et dans l'environnement sonore saturé d'un pub en est une autre). La AllYourBase est définitivement une conférence d'une grande qualité et très bien organisée, à laquelle j'aurai plaisir à assister de nouveau.
Exceptionnellement je voudrais terminer ce compte rendu par une petite aparté personnelle. Cette journée du vendredi 13 novembre s'est malheureusement terminée sur les évènements tragiques que l'on sait. Je suis reparti de Londres le lendemain matin, et les quelques personnes que j'ai pu croiser, la réceptioniste de l'hôtel, ou l'officier des douanes m'ont tous témoigné très naturellement beaucoup de sympathie et de compassion, destinées à travers moi je pense à tous les Français. Je les remercie vraiment pour ça.
Vous trouverez le compte rendu de la matinée ici, et les vidéos des différentes interventions là.


