Analyser du Texte via Machine Learning (2/2)
Introduction
Pour rappel, notre l'objectif de cet article en deux parties est d'arriver a un modèle qui nous permettrait de catégoriser des articles de presse dans la catégorie appropriée selon des catégories prédéfinies.
Dans la première partie de notre article publié sur le Blog ESENS, nous avons pu voir comment créer des modèles de catégorisation avec Tensorflow de 0.
Nous avons également pu observer que les résultats n'étaient pas très probants (une précision de 75% dans un contexte de production parait inimaginable) et que la création d'un modèle simple de 0 avec Tensorflow demande au final pas mal de connaissances en Machine Learning d'un point de vue mathématique, ou en tout cas de l'ensemble des fonctionnalités qu'offre Tensorflow.
Heureusement, les avancées de ces dernières années en matière de Deep Learning nous offrent la possibilité de ne pas commencer de rien, comme nous l'avons fait précédemment, mais plutôt d'utiliser des modèles pré-entraînés que nous allons ensuite affiner avec nos propres jeux de données...
BERT
Bidirectional Encoder Representations from Transformers, ou BERT, est justement un modèle de Machine Learning pré-entraîné pour les modèles NLP destinés à être affinés selon des spécifiques.
Originellement publié par Google en 2018 et entraîné sur d'énormes jeux de données anglais, BERT a pour énorme avantage, de par sa bi-directionalité de lecture (de gauche à droite et de droite à gauche), d'avoir une compréhension de contexte jusque-là inégalée.
Cependant, dans le contexte de notre projet, j'aimerais catégoriser des articles en français et un modèle pré-entraîné sur un jeu de données anglais risquerait de générer plus de problèmes que de solutions.
Heureusement, depuis la publication du premier BERT, de nombreux modèles entraînés sur divers corpus ont fait leur apparition et la France n'est pas dépourvue de ses modèles BERT.
Parmi eux, deux modèles issus de la recherche française se démarquent : FlauBERT et CamemBERT, tous deux entraînés sur de larges jeux de données en langue française.
Dans cet article, je vais donc me servir de ces modèles pour tenter d'entraîner mon propre modèle de catégorisation d'articles de journaux en français.
Hugging Face
Lors de mes premiers tests avec TensorFlow pour l'affinage de modèles BERT, je me suis retrouvé nez-à-nez avec un problème de taille : le support des modèles BERT pour Windows.
En effet, il m'était impossible de lancer les modèles que je créais depuis ma machine Windows. ☹️
Cette problématique m'a amené a effectuer des recherches pour trouver des solutions alternatives à TensorFlow. L'une d'elle a particulièrement retenu mon attention et c'est celle que j'utiliserai par la suite dans cet article : Hugging Face.
Entreprise créée en 2016 par deux français (à l'origine pour créer un Chatbot), Hugging Face a pivoté et est devenue en quelques années une communauté essentielle dans le traitement de langages naturels, avec pour objectif la démocratisation du NLP.
Hugging Face met à disposition un ensemble de librairies permettant le traitement de jeux de données et la création de modèles en permettant une interopérabilité TensorFlow, Python, et diverses autres.
Si je ne pouvais pas lancer l'apprentissage de modèles BERT sur TensorFlow, je peux donc toujours le faire en PyTorch avec Hugging Face et m'assurer d'avoir un modèle qui sera compatible TensorFlow.
De plus, Hugging Face permet le partage de nombreux jeux de données et de modèles pré-entraînés via ses référentiels https://huggingface.co/models et https://huggingface.co/datasets
Réutiliser un modèle entraîné
Parmi ces référentiels, nous pouvons déjà trouver des modèles pré-entraînés de type BERT, et même de type FlauBERT ou CamemBERT, comme le modèle de Théophile Blard; un modèle CamemBERT entraîné sur un jeu de données de critiques AlloCiné, afin de déterminer la positivité d'un texte en français.
Prenons un peu de temps pour commencer à vous prouver la différence de précision entre un modèle BERT anglais affiné avec des exemples anglais et un modèle BERT français affiné avec des exemples français.
Pour notre premier exemple, utilisons le modèle suivant, basé sur le modèle BERT anglais RoBERTa et affiné avec des exemples anglais issus de Twitter : https://huggingface.co/cardiffnlp/twitter-roberta-base-sentiment
Comme vous pouvez le voir, il est très facile, avec Hugging Face, d'avoir un modèle fonctionnel pour vos exemples, tant que le modèle dont vous avez besoin existe dans leur référentiel.
Cela dit, bien que les résultats pour nos exemples en anglais soient pertinents, les résultats pour nos exemples français le sont bien moins.
Essayons donc avec le modèle mentionné précédemment, consistant en un modèle CamemBERT affiné sur la base de critiques AlloCiné :
Théophile Blard, French sentiment analysis with BERT, (2020), GitHub repository, https://github.com/TheophileBlard/french-sentiment-analysis-with-bert
On peut voir ici que les résultats pour nos exemples en français sont bien plus pertinents !
Si nous souhaitons catégoriser des articles de journaux rédigé dans la langue de Molière, il semble donc bien plus effectif de trouver un modèle FlauBERT ou CamemBERT, affiné selon des exemples français.
Malheureusement, il n'existe pas de modèle de ce type dans Hugging Face et nous allons donc devoir faire, en quelque sorte, ce qu'a fait Théophile Blard, c'est à dire affiner un modèle FlauBERT ou CamemBERT afin qu'il puisse catégoriser nos articles.
Affiner un modèle existant pour l'analyse de sentiment
La prochaine étape de notre projet est maintenant d'affiner notre propre modèle.
Afin de mieux comprendre comment cela fonctionne, nous allons tout d'abord essayer de reproduire le travail de Théophile Blard, mais avec un modèle FlauBERT plutôt que CamemBERT.
Commençons par récupérer le jeu de données AlloCiné depuis le dépôt publique d'Hugging Face :
Une fois cela fait, nous pouvons créer notre modèle et lancer l'entraînement.
Pour cela, nous allons utiliser l'utilitaire "Trainer" d'Hugging Face, qui nous permettra d'affiner un modèle existant à partir de jeux de données et d'un minimum de configuration.
Commençons donc par cette configuration.
L'utilitaire "Trainer" configuré, il ne nous reste plus qu'à le lancer...
A attendre...
...
Et à le sauvegarder.
Après de longues heures, notre modèle est prêt à être validé.
Mais passons cette partie validation de notre modèle que nous avons suffisamment abordée dans la partie précédente et exécutons plutôt notre modèle généré sur les exemples utilisés pour tester le modèle AlloCiné CamemBERT.
Les résultats semblent concluants. On peut maintenant dire que nous savons affiner un modèle BERT sur la base d'un jeu de données grâce à Hugging Face.
J'aimerais ici relever la facilité déconcertante avec laquelle il est possible de faire un modèle NLP très précis avec Hugging Face. On est maintenant loin du besoin de connaissances poussées qu'il fallait il y a encore quelques années pour pouvoir créer de vrais modèles fonctionnels !
Cas pratique : catégorisation d'articles de journaux
Mais trêve de bavardages et passons à notre cas pratique : la catégorisation d'articles.
Comme nous l'expliquions dans notre précédent article, l'une des parties importantes de la création d'un modèle, peut-être même la plus importante, est la création du jeu de données d'entraînement.
Dans notre cas, partons d'un jeu de données récupéré de manière éthique à partir de l'ensemble des archives de journaux d'un site de presse et commençons par analyser les données qu'il contient.
Ce qui nous intéresse dans un premier temps, c'est d'analyser la distribution de notre jeu de données afin d'évaluer de sa propreté par rapport à notre cas d'apprentissage.
Commençons donc par analyser notre jeu de données.
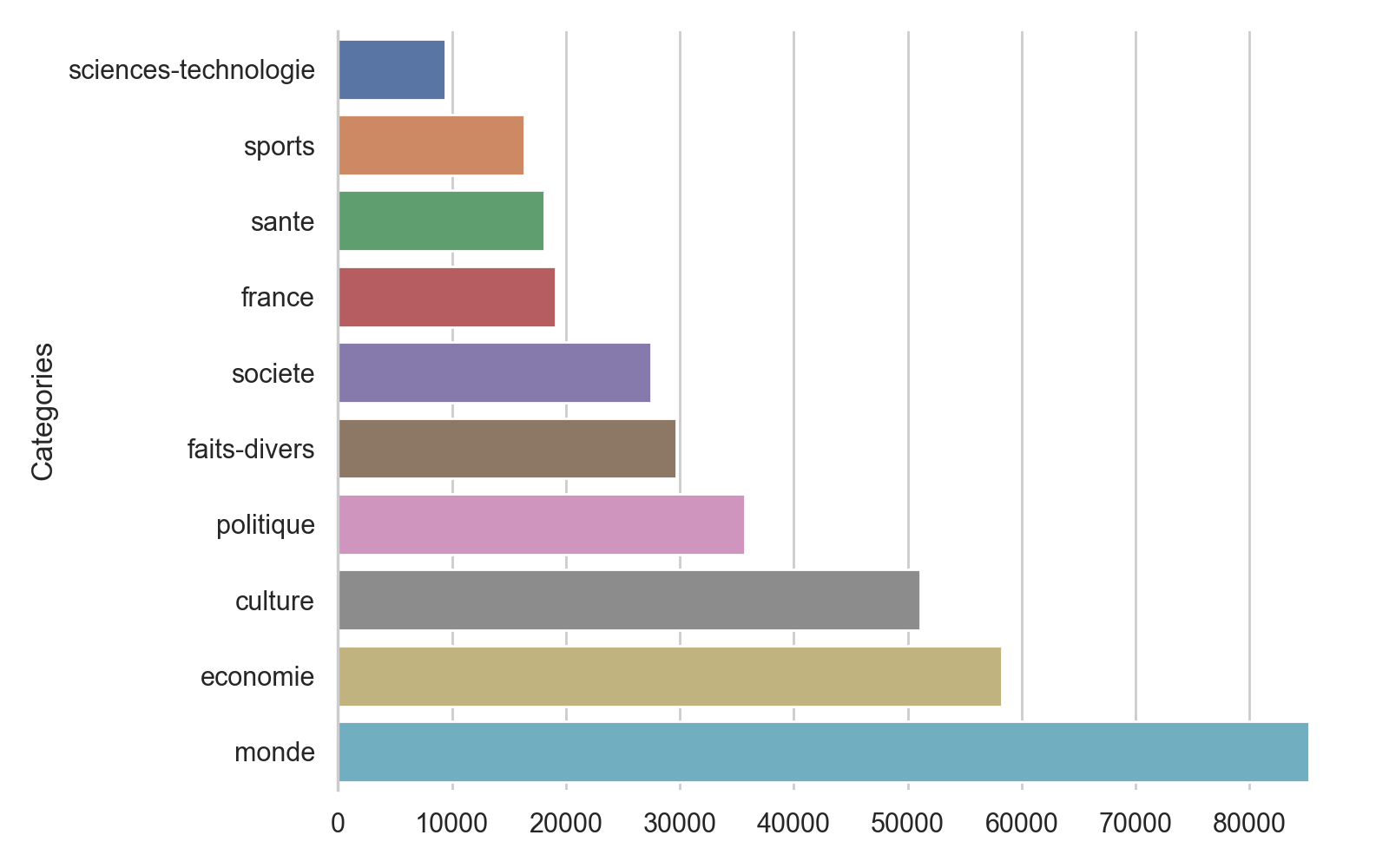
Celui-ci contient à l'heure actuelle 447 563 articles répartis de la manière suivante :
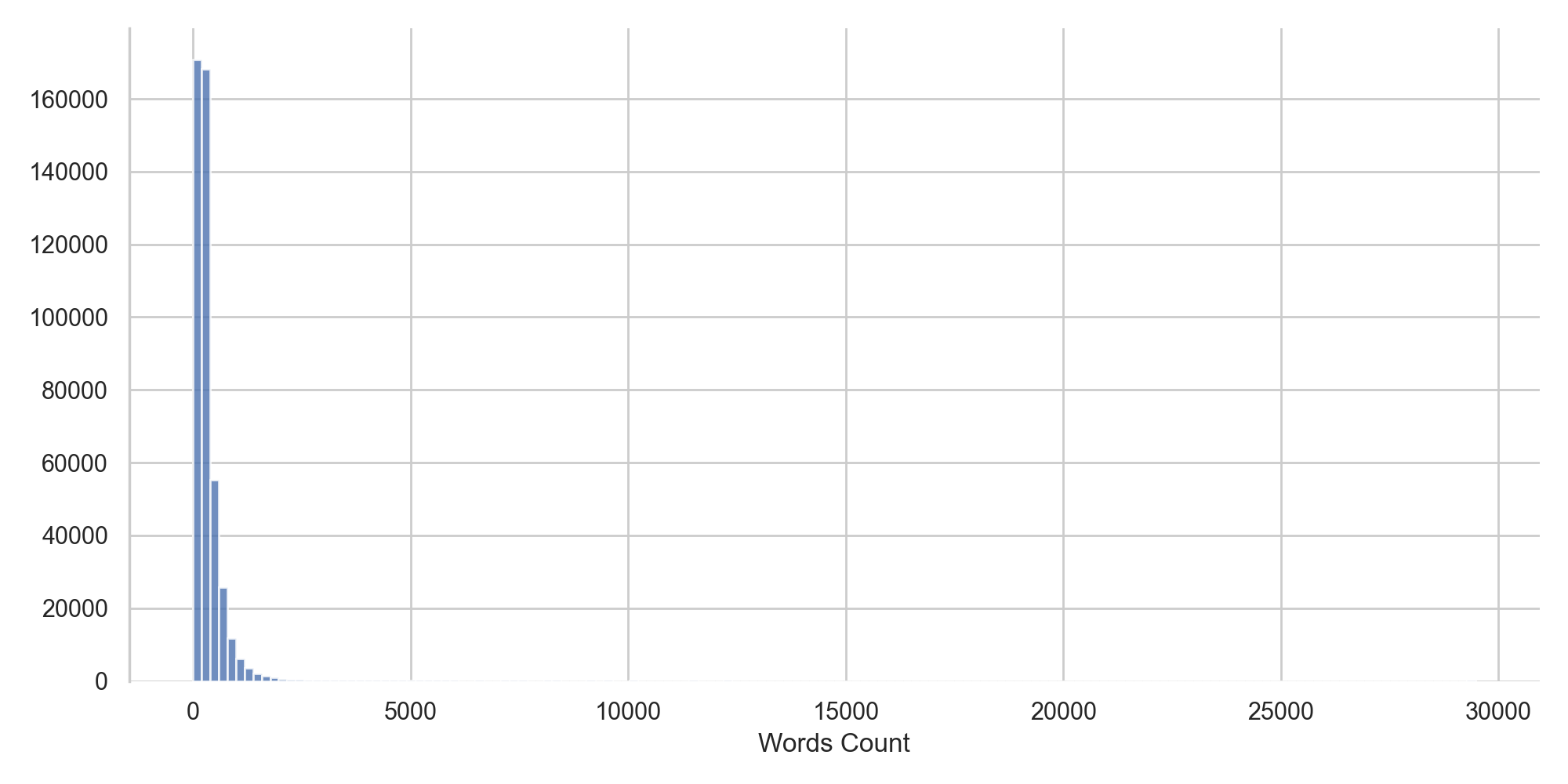
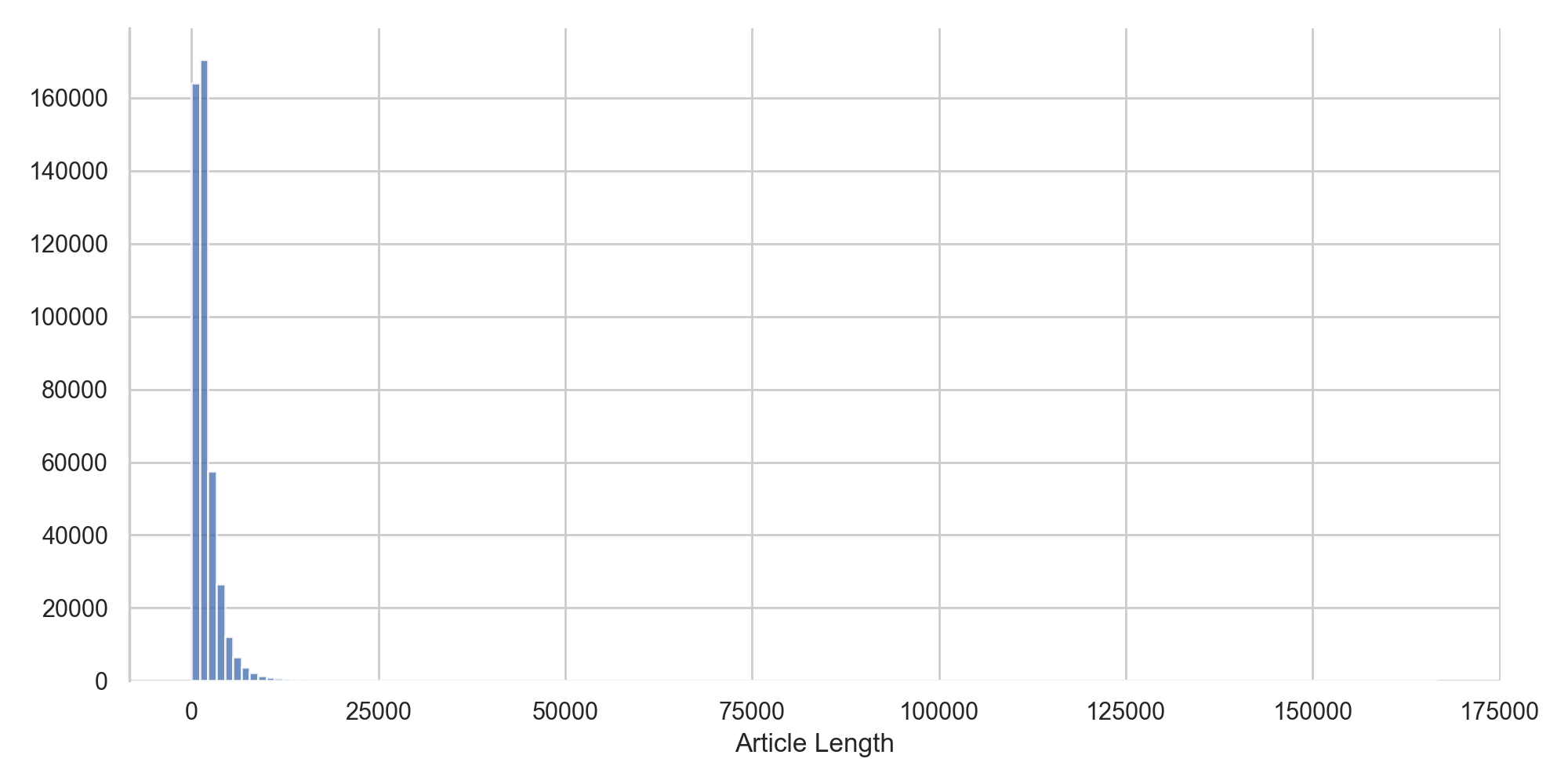
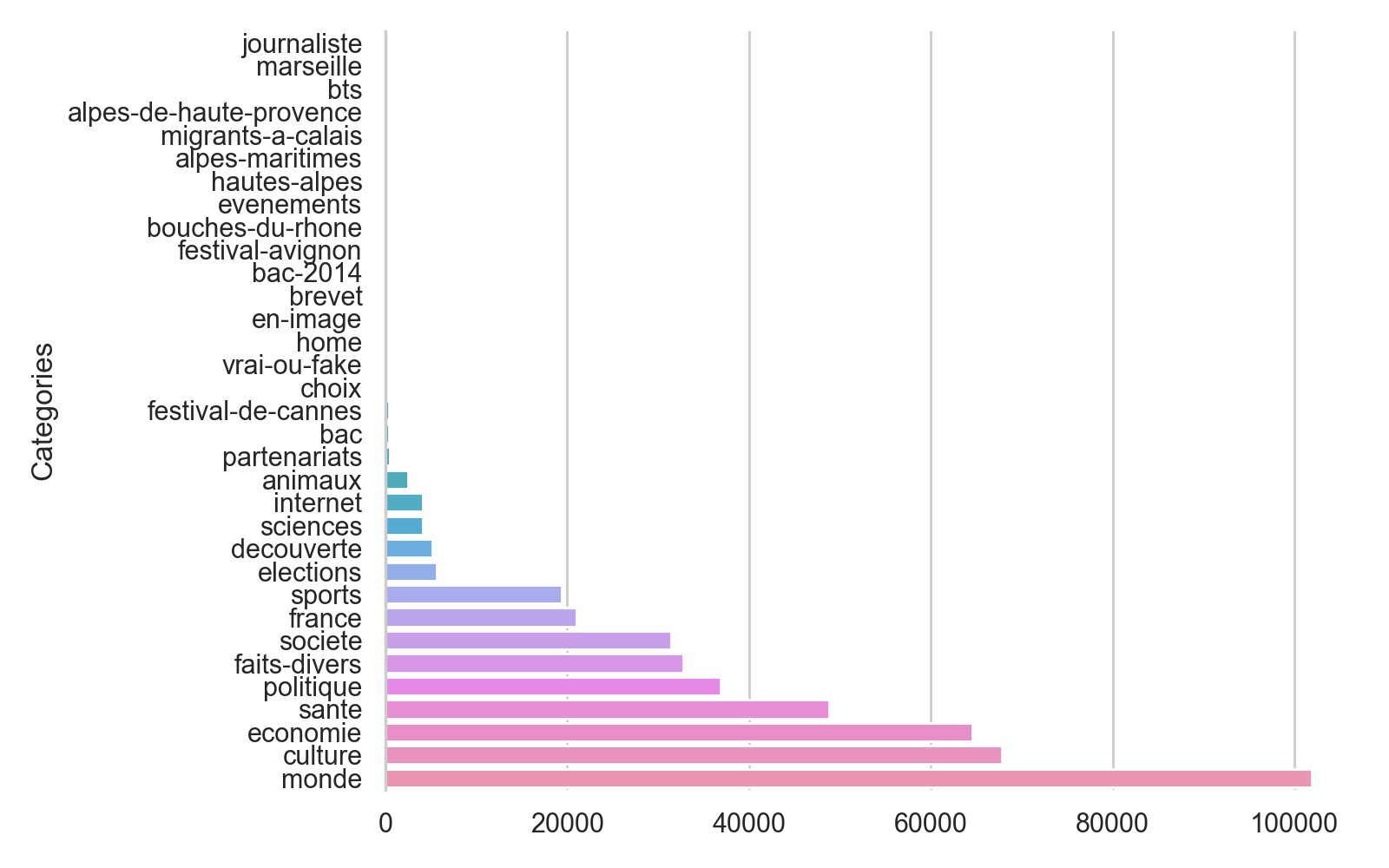
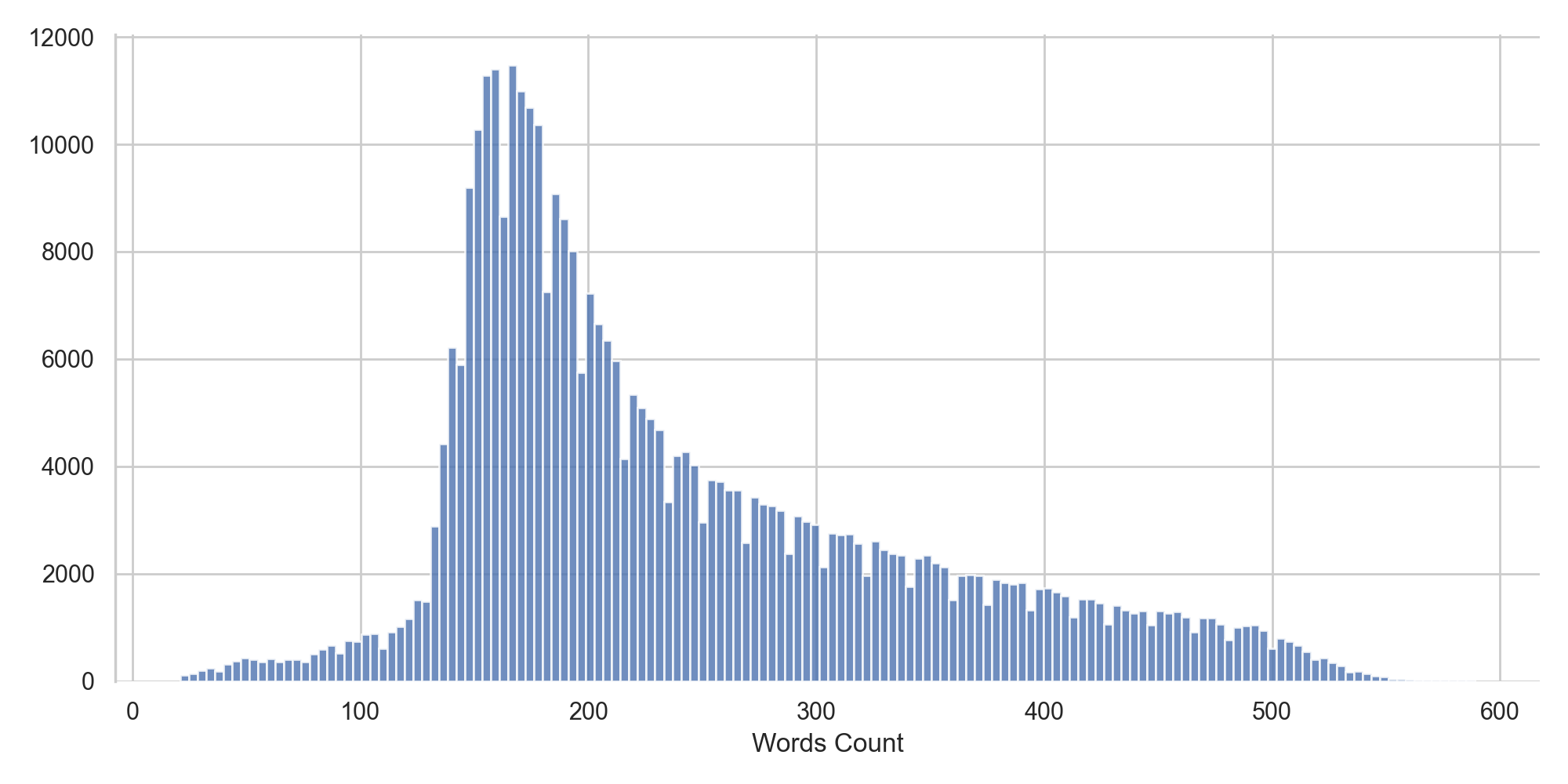
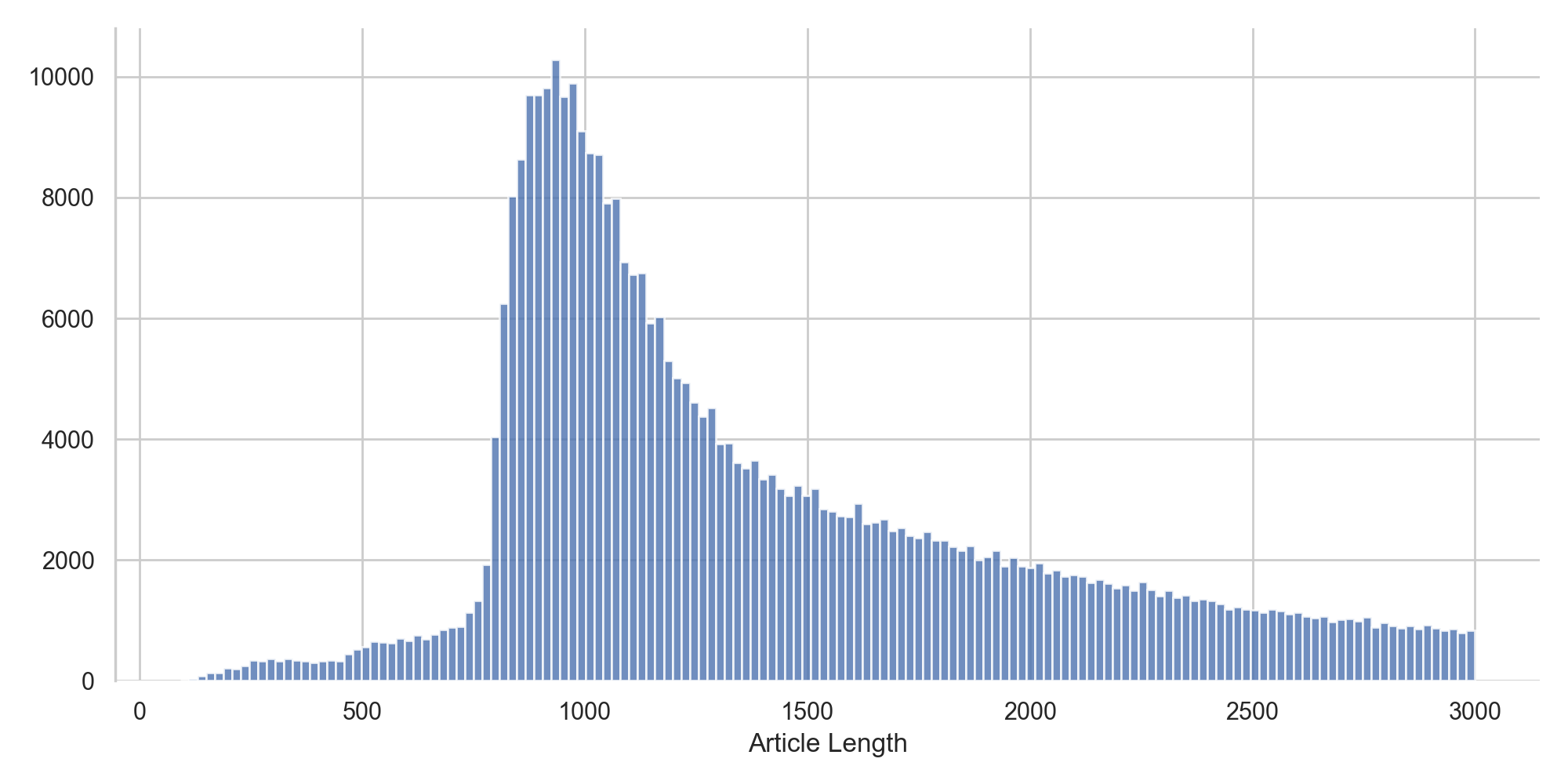
On observe tout d'abord que la distribution de la taille des articles est bien trop variable. Nous allons donc filtrer les articles trop petits ou trop gros pour pouvoir déterminer leur catégorie.
Nous voyons également que les catégories ne sont pas très harmonieuses et nous voulons rester suffisamment générique pour que les catégories de ce site de presse puissent-être appliquées aux autres sites pour lesquels nous voudront déterminer des articles.
Nous allons donc également filtrer et réunir certaines des catégories afin d'avoir un ensemble de catégories plus propre :
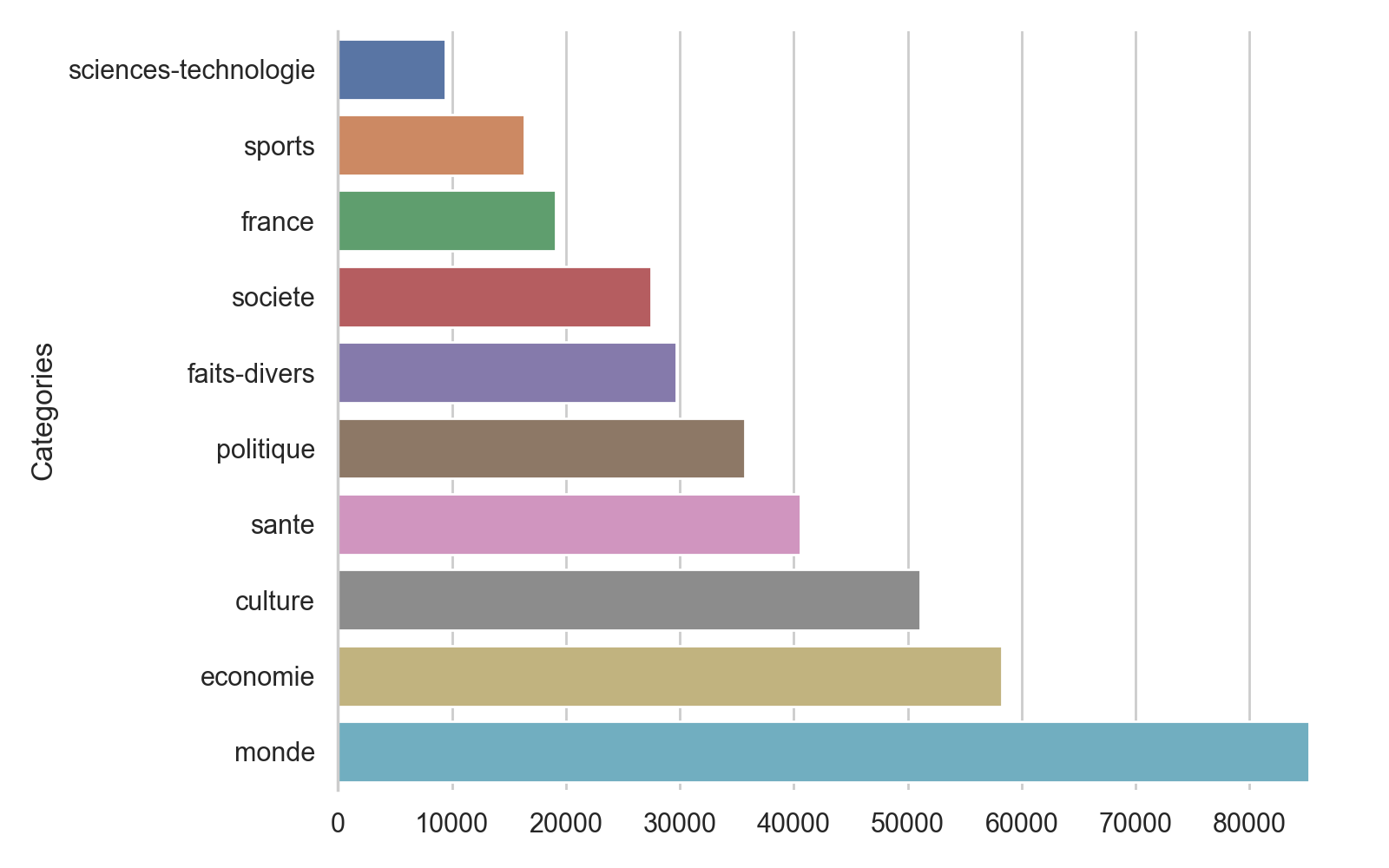
Tout cela semble plus propre, mais une chose interpelle : le nombre d'articles 'santé' semble bien élevé. Cela peut évidemment s'expliquer par la présence quotidienne de la Covid dans nos journaux entre 2020 et 2021. Cela me semble cependant problématique, les articles autour de la Covid étant régulièrement des articles traitant de l'impact du virus dans la vie sociale, politique, économique, etc., utilisant ainsi un champs lexicales et des tournures de phrases généralement non associés à la santé.
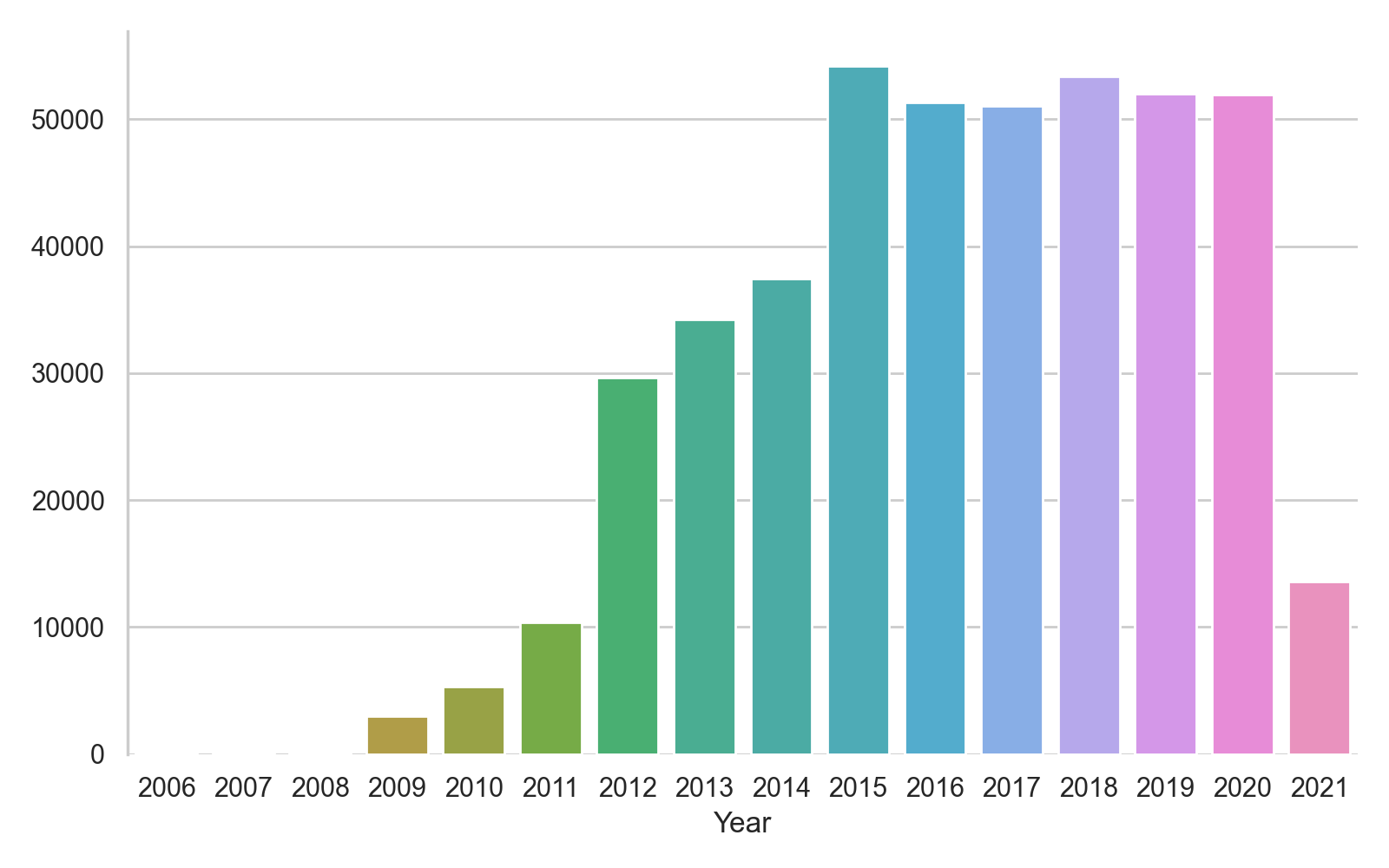
Commençons par confirmer notre hypothèse en ne comptant que les articles de santé par année :
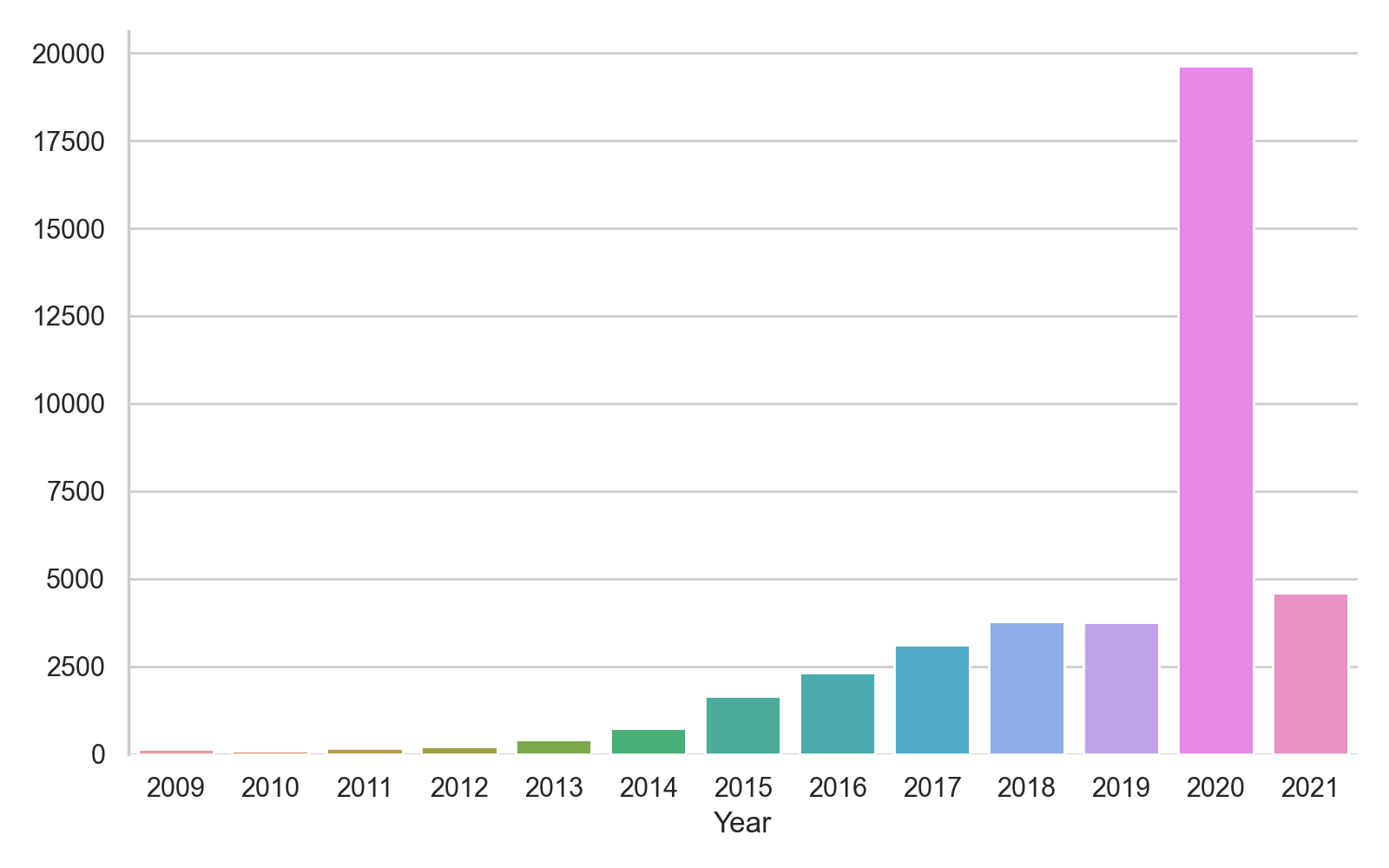
Comme vous pouvez le voir, l'hypothèse semble se confirmer avec une explosion des articles de santé à partir de 2020. On va donc essayer d'éliminer les articles faisant référence au virus :
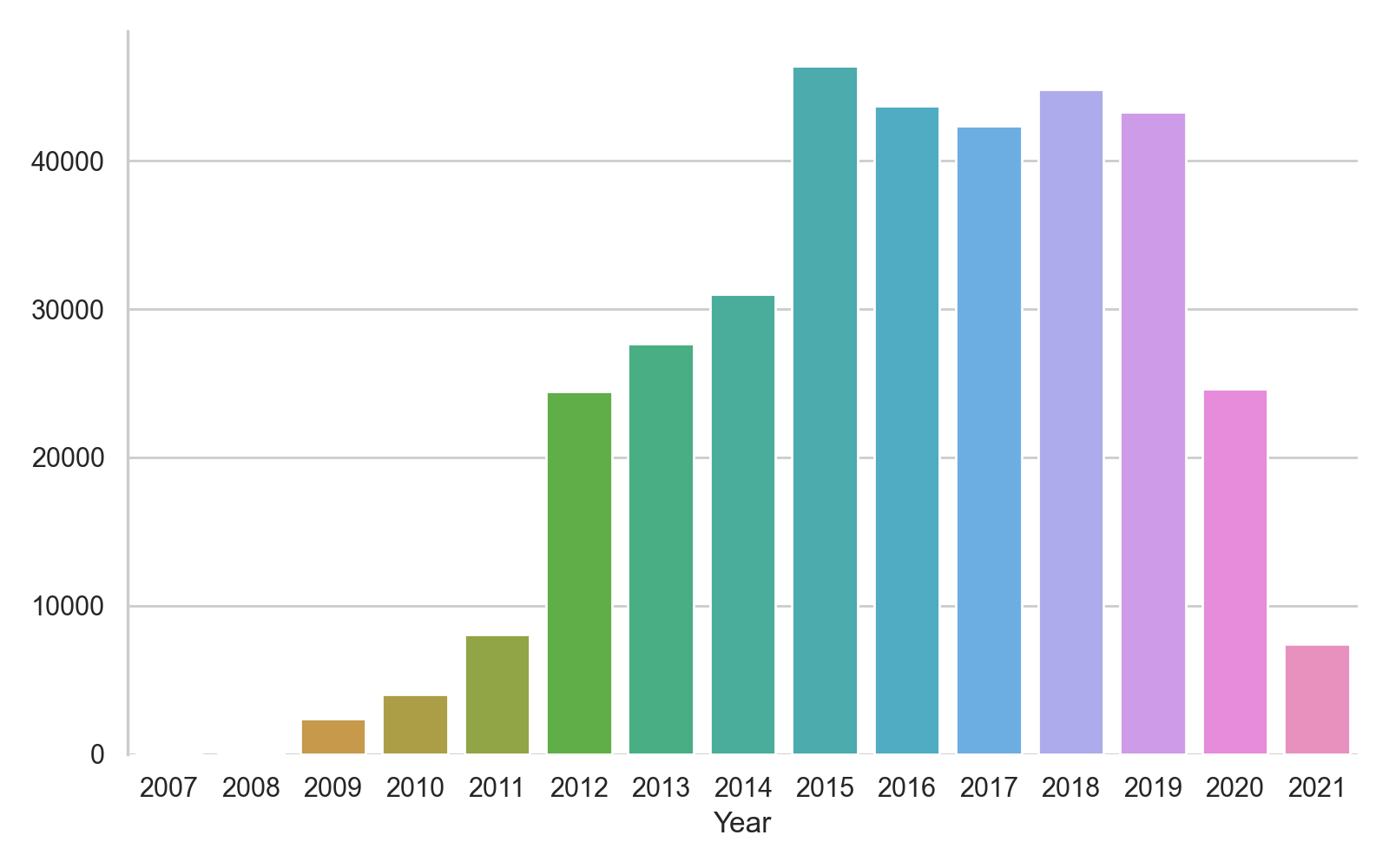
Puis, préparons notre modèle :
Et lançons l'entraînement :
Comme vous pouvez le voir, l'entraînement a été long, très long : presque 5 jours et demi à le faire tourner.
Bien que les performances de l'algorithme soit plutôt satisfaisantes, avec une précision de près de 80% pour un premier essai, si nous souhaitions essayer d'améliorer ces performances, nous aurions besoin de soit beaucoup de patience, soit de plus grosses machines pour pouvoir effectuer les calculs plus rapidement.
En attendant, regardons un peu ce que nous donne comme résultat le modèle pour les trois exemples suivants issus du site d'actualités 20 minutes :



Ce qui nous donne en sortie :
Vous observerez juste une petite différence au niveau du dernier article, 20 minutes catégorisant l'article comme un article "Monde" quand nous le catégorisons comme un article 'économie'. Mais notre catégorisation ne semble pas du tout incorrecte pour autant.
Voilà ! Nous avons désormais créé un outil permettant de catégoriser des articles selon un ensemble de catégories prédéfinies.
A l'avenir, j'espère pouvoir étudier un peu plus comment affiner ces prédictions, mais il faudra dans un premier temps trouver comment pouvoir entraîner ces modèles de manière plus performante.
J'espère tester ainsi trois pistes qui pourrons potentiellement être combinées, facilitant ainsi grandement la création de modèles complexes.
Je vous laisse donc avec ces nouvelles pistes, si vous souhaitez les explorer par vous-même :
- La recherche HyperParameter d'Hugging Face
- Google Colab
- L'entraînement sur TPU
Vous pouvez également retrouver l'ensemble du code de notre projet dont il est question dans cet article, ainsi que les modèles associés, sur notre GitHub.
A très bientôt !
------------------------------
Article rédigé par Manu, Tech Lead Full Stack & Manager du Lab ESENS | Retrouvez tous nos articles tech sur le Blog !
Vous êtes à la recherche d'un nouveau challenge technique ? Rejoignez l'équipe ESENS en postulant à nos offres d'emploi !


