Composants d'une Architecture Big Data

Le monde du stockage et de l’exposition de données est en ébullition depuis quelques années. L’accélération constante de la collecte de données et la diversité des informations à stocker, traiter et utiliser constitue un challenge nouveau qui a montré les limites du modèle de base de données relationnelles qui étaient hégémoniques des années durant.
Le Big Data est né, et avec lui la nécessité de choisir des technologies de stockages adaptés à chaque usage. Au travers de cet article, nous allons simuler un SI complet, possédant plusieurs besoins, et proposer des choix de composants d’une architecture complète.
Exemple pour cet article
Dans le cadre de cet article, nous imaginerons être dans le cas d’une architecture Big Data à mettre en place pour répondre aux cas d’usages suivants :
Nous souhaitons avoir une cartographie en temps réel (ou au plus proche) de la disponibilité des vélib, autolib, métro et uber sur la ville de Paris.
Nous souhaitons pouvoir informer par SMS (ou notification) nos utilisateurs du meilleur moyen de se rendre à leur prochain rendez-vous (enregistré dans Google agenda), en prenant compte de la disponibilité des moyens de transport, du temps de parcours prévu et de la météo (pour ne pas proposer de velib sous la pluie).
Nous souhaitons également pouvoir réaliser des statistiques et de l’exploration de données sur l’historique des conditions météo, des temps de parcours, de la disponibilités des autolibs, vélibs et uber.
Limitation et périmètre
L’objectif de cet article est de proposer une articulation des différents composants de l’architecture pour répondre au mieux à chacun des besoins.
Les technologies proposées ne sont pas comparées aux différents concurrents existants, qui selon les cas pourront être beaucoup plus adaptés.
Nous ne nous pencherons pas non plus en détail sur le code et les spécificités de chaque langages utilisés, afin de garder une vision la plus macro possible.
Quelles bases de données pour quel usage ?
Les bases de données ont longtemps été uniquement relationnelles et permettaient d’accéder rapidement à des informations stockées, ces informations étant toujours exactes.
L’arrivée du “Big Data” a imposé une caractéristique supplémentaire aux bases de données : La distributivité (ou scalabilité).
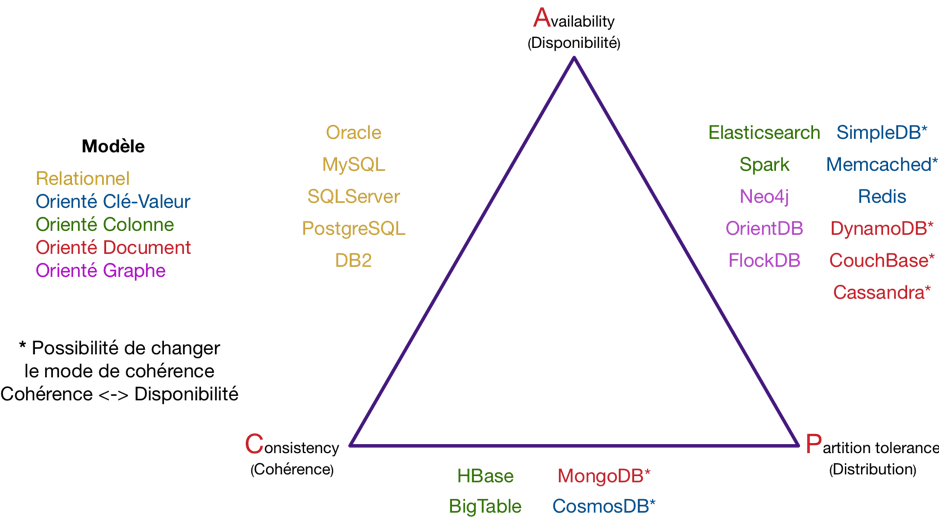
Malheureusement, il a été montré en 2000, par Eric A. Brewer le théorème dit de CAP reposant sur trois propriétés fondamentales pour caractériser les bases de données :
Dans toute base de données, vous ne pouvez respecter au plus que deux propriétés parmi la cohérence, la disponibilité et la distribution.
(En anglais : Cohérence = Consistancy, Disponibilité = Availabilty et Distribution = Partition tolerance. C, A, P.)
Les bases NoSQL (Not only SQL) sont venues répondre aux nouveaux besoins de scalabilité.
On distingue donc des bases CA, AP ou CP, que l’on peut les répartir selon le graphique suivant:
Cas d’usages autours d’une architecture
Dans le cadre de l’exemple introduit précédemment, on distingue plusieurs besoins bien précis autours de la donnée :
Cartographie en temps réel des données
Cela demande une mise à disposition temps réel des données, appelé aussi stockage à chaud. Ces données doivent pouvoir être facilement stockées et restituées en grand volume.
Les bases doivent être Disponibles et Distribuées (AP).
Dans notre exemple, nous utiliserons Elasticsearch et Kibana.
Traitement en temps réel pour envoi SMS
Il faudra pour cela pouvoir lancer des traitements en temps réel en fonction de l’arrivée d’informations, pour permettre de savoir rapidement si un SMS doit être envoyé, et quelles informations mettre dedans.
Ce besoin ne nécessite pas de stockage particulier, mais de déclencheurs et de traitement en temps réel, appelés aussi traitement à chaud.
Stockage des historiques de données
Afin de pouvoir réaliser des études de masse, nous allons devoir stocker l’intégralité des données et historiques des données collectées. Ces dernières représenteront potentiellement des grands volumes de données, ayant des formats différents selon les sources.
En revanche, il n’est pas nécessaire d’avoir un accès instantané à ces données qui pourront être chargées à la demande pour les besoins futur. On parle alors de stockage à froid.
Les bases devront être Cohérentes et Distribuées (CP).
Nous utiliserons dans notre cas Hadoop HDFS.
Récupération et traitement des historiques de données
Les données stockées à froids, pour être exploitées, nécessiteront d’être traitées en masse par des batchs, afin par exemple d’être mis en forme pour utilisation dans dans rapports de BI, ou dans des référentiels de données.
Ces traitement sont fait par batch, demandent d’être très performant sur des grands volumes, mais sans besoins d’immédiateté des résultats. On parle alors de traitement à froid.
Dans notre cas, nous parlerons de batchs Scala.
Mise à disposition de données d’historiques
Une fois retraités, les données pourront être mise à disposition de services annexes, pour de la data science, des recherches, des utilisation BI etc.
Les données seront alors normalisées par les traitements de préparation, et leur volume sera relativement constant et prévisible.
Ces bases devront être Disponibles et Cohérentes (CA).
On utilisera alors dans notre cas une base relationnelle Oracle SQL.
Architecture
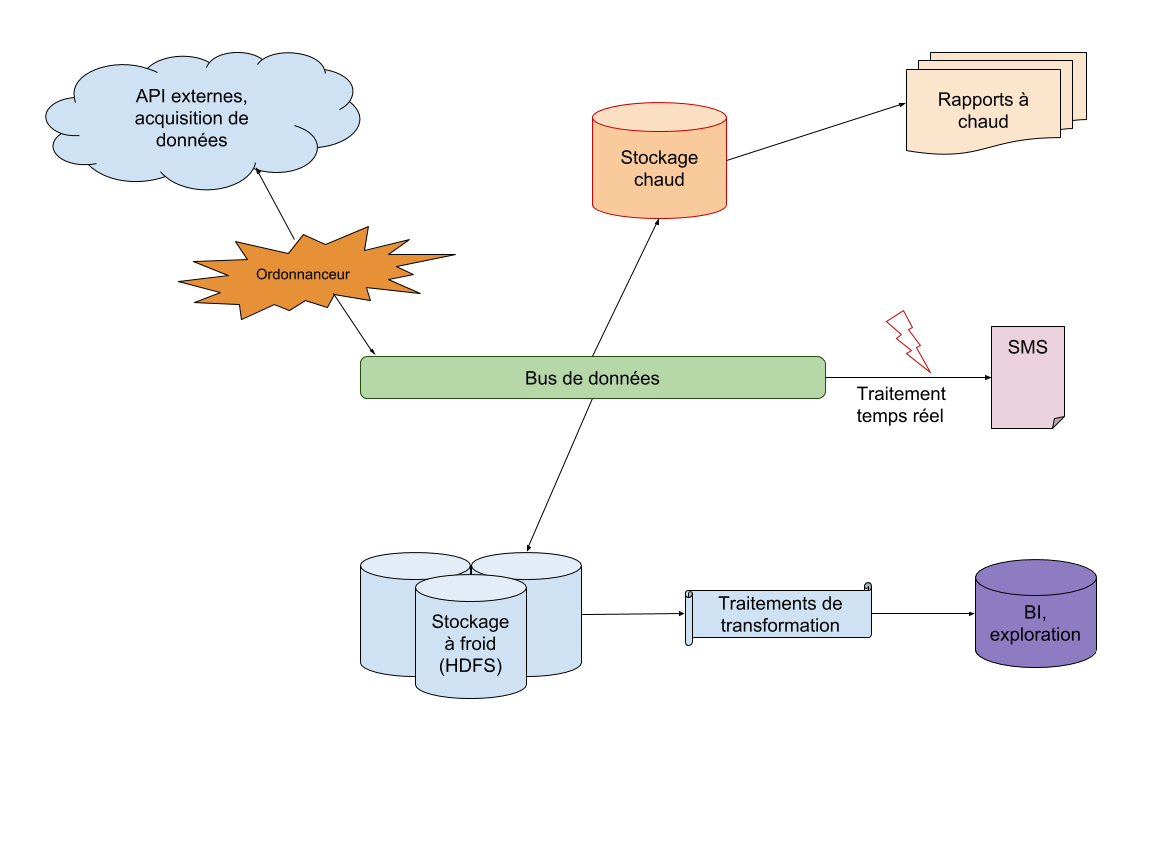
Nous pouvons schématiser l’architecture de notre cas de la façon comme sur le schéma ci-dessus.
La première phase est l’acquisition de la donnée depuis des API externes entre autre.
Cette acquisition peut être faite en utilisant l’outil de processing NIFI par exemple.
Les données sont ensuite transmise à un bus de données qui véhiculera les informations à travers le SI. Pour faire cela, nous utiliserons ici Kafka.
Les données devront être immédiatement stockées dans le stockage à chaud afin d’être mises à disposition des rapports et usages internes. Nous présenterons pour cela Elasticsearch et Kibana.
Les données devront être également utilisées dès leur mise à disposition par les traitements à chaud, afin de déclencher au besoin l’envoi de SMS. C’est Spark Streaming qui sera ici utilisé.
Enfin, les données seront stockées dans le stockage à froid. Nous parlerons ici de Hadoop (HDFS).
Ces données froides pourront au besoin être traitées, mise en forme et exploitées pour différents types d’usage. Nous évoquerons pour cela Scala, et Oracle SQL.
NIFI (processing)
Contraction de NIagara FIles, NIFI est un outil d’ordonnancement développé initialement par la NSA qui a ensuite donné l’outil à la fondation apache.

NIFI est fait pour permettre une l'acquisition, le traitement et la mise à disposition rapide de données. Son fonctionnement est proche de celui d’un ETL. L’outil se base sur une interface graphique de paramétrage de microservices monotâches, reliés par des queues. Les donnée transitent de service en service par des queues.
Il permet d’orchestrer facilement des récupérations d’informations par API et de les transmettre à des files Kafka.
Dans notre application, NIFI pourra être utilisé pour réaliser des appels à intervals réguliers vers les services Google Calendar pour récupérer les informations de réunions des utilisateurs, vers les smartphones des utilisateurs pour récupérer leurs position GPS, et ainsi réaliser des appels sur les API de Google Maps pour connaître les temps de parcours selon les modes de transport, vers la RATP, Velib et Autolib pour connaitre les disponibilités autours de l’utilisateur, mais également récupérer la météo autours de l’utilisateur.
Au fur et à mesure de leur mise à disposition, ses données seront envoyées vers Kafka, pour pouvoir être ensuite utilisées par les différents services de notre SI.
Kafka
Kafka est un bus de transport de messages (ou données).
Kafka stocke des messages, dans l’ordre de réception, quel que soit le type de message, et de façon simplement scalable.

Les consommateurs sont responsable de leurs lectures qu’ils récupèrent lorsqu’ils le souhaitent en pull (par opposition au push).
L’intérêt de Kafka réside en la mise à disposition simple d’informations diverses en un endroit unique. Les données restent disponibles pour relecture, et il est à la charge des consommateurs de choisir le type de données qu’ils veulent récupérer.
Les consommateur possèdent des identifiants de groupe afin d’éviter la prise en doublons d’informations lors des traitement parallélisés.
Inconvénient : Kafka n’est pas une solution de stockage, mais de mise à disposition des données en temps réel. La capacité d’historique est donc restreinte.
Dans notre application, les différents services pourront écouter les messages qui arriveront en provenance de NIFI. Les différents type de message (retours d’une API ou d’une autre, message émis par un traitement interne…) seront récupérés ou non par des traitements automatiques pour réaliser des actions. Nous verrons cela plus en détail dans le paragraphe sur Sparkstreaming.
ELK
Elasticsearch est un base de données orienté colonne et document, dont la spécificité est l’indexation des contenus et le moteur de recherche associé. Il permet entre autre de faire de la recherche full-text dans des documents longs.

Elasticsearch est souvent associé à Logstash (un outil de persistance et traitement des log applicatifs) et Kibana (dont nous parlerons ensuite) pour former la suite ELK.
Comme MongoDB et beaucoup d’autres, Elasticsearch stock et expose des documents JSON, ce qui rend son intégration dans un SI extrêmement simple et rapide.
Kibana
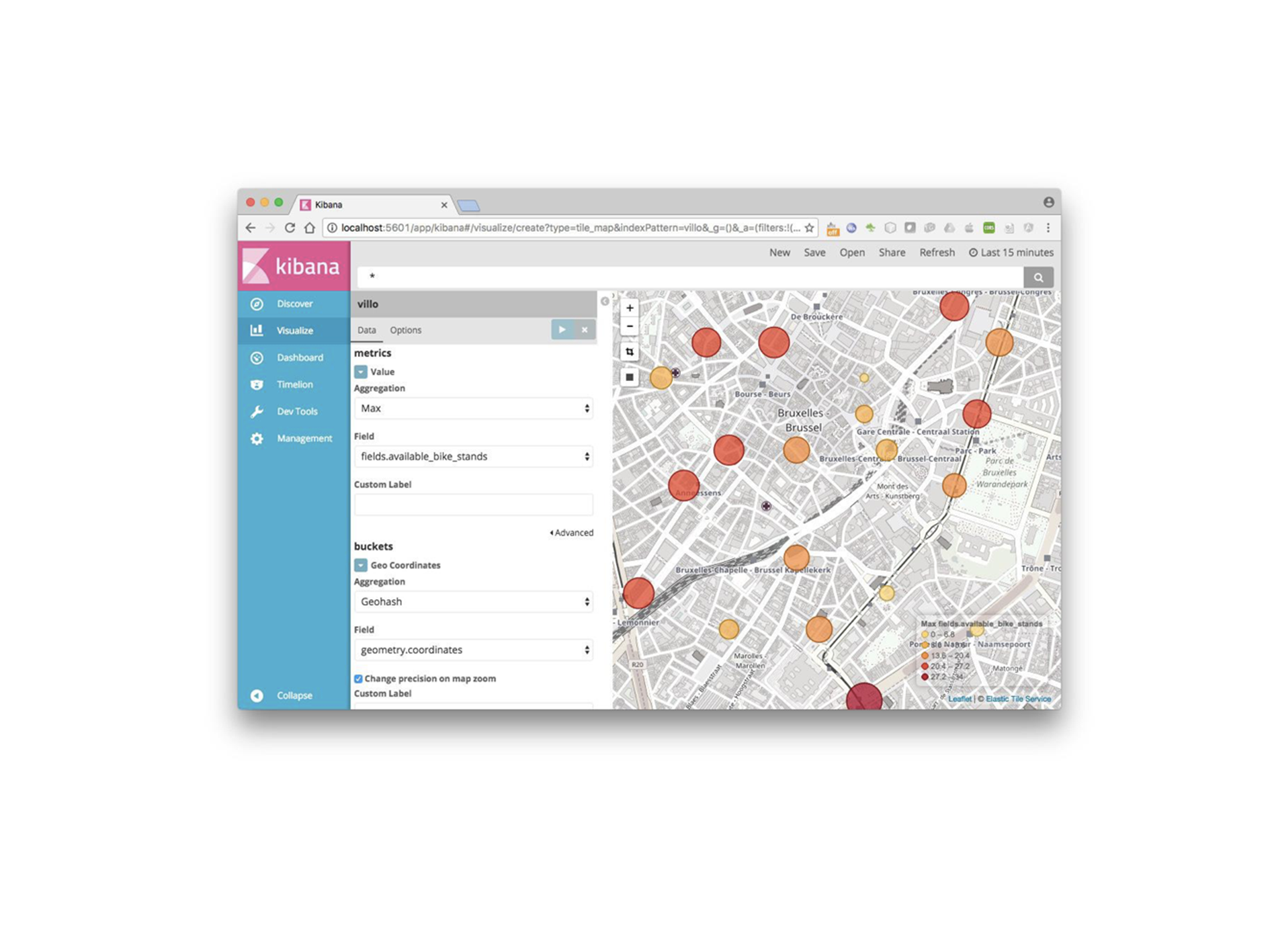
Kibana est un outil basé sur des indexs Elasticsearch, qui permet de réaliser des rapports simplement et via une interface graphique.

Selon le type de données, Kibana peut générer des statistiques, et nuages de mots, des courbes d’évolutions dans le temps, mais également des cartographies.
Lorsque les données sont disponibles en temps réel dans elasticsearch, les rapports sont actualisés également, permettant d’avoir un suivi en temps réel dans des rapports.
Inconvénients : La suite ELK est très pratique pour visualiser ou utiliser de la donnée rapidement et simplement. Pour autant, les traitements d’indexation ne permettent pas de fonctionner correctement avec de très grands volumes de données.
Pour résoudre cela, ELK est distribué sur différents serveurs, mais dans ce cas les modifications ne sont pas faites sur un modèle transactionnel, et donc la cohérence des données n’est pas assuré.
Dans notre application : Dans le cas de notre application, des jobs pourraient être branchés à Kafka pour insérer les données fraîches dans Elasticsearch. Chaque job pourrait traiter un type de donnée (retour API par exemple), et réaliser une première transformation.
Les données ainsi transformées pourraient être mise à disposition d’autres services du SI, ou visualiser directement avec Kibana pour constituer les rapports de notre premier cas d’usage.
Régulièrement, il faudra purger les données trop anciennes, qui n’ont pas leur place dans le cas d’usage et pourraient réduire les performances.
Spark Streaming
Spark Streaming est un outil de Spark (apache) qui est fait pour réaliser des traitements de flux. C’est ce que nous appelons des traitements à chaud.

Les traitements sont généralements écrit en Scala, même si Python ou Java peuvent être utilisés. Ils utilisent des données “live” en étant généralement branchés sur des files Kafka.
Les résultats des traitements sont généralement soit réinjectés dans Kafka, soit déclenchent des actions externes (envois API, insertion de données dans des bases etc.)
Inconvénients : Ces traitements sont fait pour traiter rapidement des données chaudes, et non pour traiter par batch de gros volumes de données.
Dans notre application : De nombreux traitement Spark Streaming pourront être utilisés, pour envoyer les informations de Kafka à Elasticsearch entre autre.
L’usage principale serait peut-être pour l’envoi de SMS. L’application devrait détecter si un utilisateur a un évènement à venir dans son calendrier, puis récupérer sa localisation et les disponibilités de moyens de transports autours de lui. En fonction des temps de trajets, eux aussi récupérés pour chaque mode de transport, des préférences utilisateurs et de la météo, le traitement doit rapidement prévenir l’utilisateur de la meilleure option pour lui.
Ce traitement utilise de nombreuses données, et les traiter en temps réel.
HDFS
Hadoop Distributed Files System (HDFS) est un système de stockage de gros volumes de données dite froide (sans urgence).

Initialement, la technologie a été pensée par les moteurs de recherche (Google et Yahoo) pour stocker les pages HTML du web, afin de pouvoir faire des traitements de référencement dessus par la suite.
Cette technologie est faite pour le stockage de fichiers volumineux de façon distribuée. Les fichiers sont découpés en sous ensembles de 128Mo, répartis par le noeud maître sur les noeuds esclaves du cluster.
Les traitements sur les données contenus dans HDFS sont réalisés par système de map/reduce, c’est à dire le déportement de chaque traitement sur les serveurs hébergeant les sous-ensembles, et la remontée et compilation des différents résultats par le serveur maître.
La distribution est donc extrêmement bien gérée. En revanche les traitements sont très complexes et donc les temps de traitement beaucoup plus longs que pour d’autre sources de données (relationnelles typiquement).
Inconvénients : Si HDFS permet de stocker de très gros volumes de données de façon distribuée, nous avons vu qu’il est difficile de réaliser des traitements rapides. Les données ne sont donc pas disponible dans des délais acceptables pour les usages temps réel.
Dans notre application : Dans notre cas, HDFS sert de stockage de grands volumes de données que sont les historiques. Ces grands volumes sont facilement récupérables par des traitements batch, qui permettent d’alimenter ensuite des bases plus adaptées avec des sous ensemble de données, potentiellement retravaillées.
Scala / Spark
Scala est un langage de programmation écrit pour être fortement scalable, compilé en bytecode Java. Le langage est particulièrement adapté pour écrire des traitements Spark, scalables et rapides sur des gros volumes de données. Nous ne décrirons pas plus le fonctionnement dans cet article.
BI / SQL
Les bases SQL sont utilisés et ont fait leur preuves depuis plusieurs décennies.
Elles répondent à des besoins de récupération rapide de données cohérentes, et leur modèle transactionnel assure un maintien constant de la cohérence de l’information.
De plus, la rigidité des modèles structurés permet d’assurer des fonctionnement constant dans le temps, et les usages multiples des données. Cette particularité est à l’origine de l’utilisation de ces bases dans les applications de Business Intelligence, du fait de la simplicité de création de cubes.

Inconvénients : Par natures, les gros volumes de données sont problématiques à stocker dans les modèles relationnels des bases SQL. Ces bases ne sont en effet pas scalables, et nécessite la mise en place de backup pour prévenir les dysfonctionnements des serveurs.
Il est également indispensable de connaître à l’avance la structure des données à stocker, et de préparer des traitements d’adaptation.
Dans notre application : Nous pouvons dans notre cas utiliser ces bases relationnelles pour de nombreuses analyses sur la donnée. Elles serviront également à faire des études de BI, analyser des évolutions, ou encore à mettre à disposition des services et API de données compilées et ne nécessitant pas le même temps réel que celui proposé par d’autres technologies plus tôt.
Pour être utilisables, les données devront être extraites des stockages HDFS, retraitées par Spark/scala pour être inséré dans les bases relationnelles.
Conclusion
Nous avons vu à travers cet exemple simple que les bases de données ont toutes des avantages et des inconvénients. Utilisées à bon escient, chacune de ses technologie peut améliorer le service globale d’un SI. En revanche il est primordiale de réfléchir de façon central à l’architecture et à l’utilisation de l'intégralité du système et de savoir faire les bon choix, au risque de se retrouver avec des problèmes de performances, des traitements peu efficace ou pire encore des pertes de données.
Article rédigé par Guillaume M. | Retrouvez tous nos articles sur le Blog ESENS !
Vous êtes à la recherche d'un nouveau challenge ? Rejoignez l'équipe ESENS en postulant à nos offres d'emploi !


