Devoxx 2015 - Jour 1

Les salles sont prêtes, les goodies officiels et le badge ont été récupérés. Il est 8h35, le hall est déjà rempli et il va bientôt falloir trouver un siège dans la salle de mon choix, où se déroulera la conf' que j'ai été forcé de sélectionner parmi au moins 8 autres (les salauds).
Et oui, aujourd'hui c'est le début de la Devoxx... Petit retour (grandement subjectif) sur cette première journée :
Hands on with Google Compute Engine - Ray Tsang (Google) - 3h
On commence donc avec un labs sur Google Compute Engine, que j'appellerais GCE par la suite pour faciliter la digestion.
Service IAAS (Infrastructure As A Service) de Google, GCE me paraît, au même titre qu'Amazon Web Services, être un élément incontournable pour les personnes qui, comme moi, sont très intéressées par les pratiques DevOps sensées apporter une stabilité opérationnelle aux développeurs via des pratiques agiles de construction et de déploiement d'applications ET de machines, de la conception à l'intégration en production.
C'est un labs, la présentation est très succincte et très classique : GCE permet la création de VM via des templates/images/configuration manuelles, de l'auto-scaling et du load-balancing. A peine 15 minutes de passées et déjà nous mettons les mains dans le cambouis.
On nous ouvre donc un accès à la plate-forme web de configuration (les 60 premiers jours sont gratuits jusqu'à une facture de 300$ mais même avec une configuration minimale tournant 24h/24 7j/7, GCE vous coûteras au minimum 12$).
S'ensuit 2h de :
- Création de machines virtuelles sur la base d'images et d'instantanés.
- Création de groupes de scaling
- Création de redirections HTTP et Réseau.
- etc...
###p
Bref, Pause dèj et c'est reparti.
Les Streams sont parmi nous ! Traitement de données en Java 8 - José Paumard (indépendant) - 3h
Ok, il est 15h30 et je n'ai pas eu ma sieste, mais quand même, il est en train de m'assommer José !
Et pourtant, la présentation s'annonçait bien, le programme étant constitué des API de traitement de données soit :
l'API Streams de Java 8
GS Collections développée par Goldman Sachs
RxJava, l'API Réactive de Netflix.
D'autant que j'avais déjà eu l'occasion de voir des vidéos du bonhomme sur les lambdas et les interfaces fonctionnelles.
Les présentations de l'API Streams et de GS Collection étaient assez claires. Streams se marie bien avec les lambdas, me parait assez concise, et dispose d'une fonction de parallélisation qui peut s'avérer très pratique si utilisée intelligemment. GS Collections quant à elle apporte un grand nombre de fonctionnalités pré-définies dans la librairie dont Streams ne dispose pas. Cependant, pas de fonction de parallélisation.
La présentation de RxJava, quant à elle, a débutée de la même manière que les autres avec un résumé des principes et des éléments principaux. Mais José a voulu continuer pendant une heure de plus sur une relecture de la documentation de chaque méthode (ou tout du moins c'est comme cela que je l'ai ressenti). Ces slides seront très intéressants à lire, mais pour une conférence, je trouve ça complètement indigeste.
La dernière partie de la présentation fut (enfin) consacrée à une comparaison des 3 librairies présentées, via leur utilisation dans un exemple concret (calcul des points apportés par un mot au Scrabble), suivie d'un bilan sur leurs performances.
RxJava, au contraire des deux autres librairies, n'est pas vraiment une librairie de traitement des données, mais plus généralement de traitement d'événements via l'extension du pattern Observateur, et l'exemple n'était que très peu adapté à son fonctionnement. Du coup, il n'est pas très étonnant qu'elle pâlisse de la comparaison dans le contexte présenté.
Mais revenons en à cette comparaison :
Streams et GS Collections se ressemblent beaucoup et dans ce contexte de traitement de données, RxJava est beaucoup plus complexe.
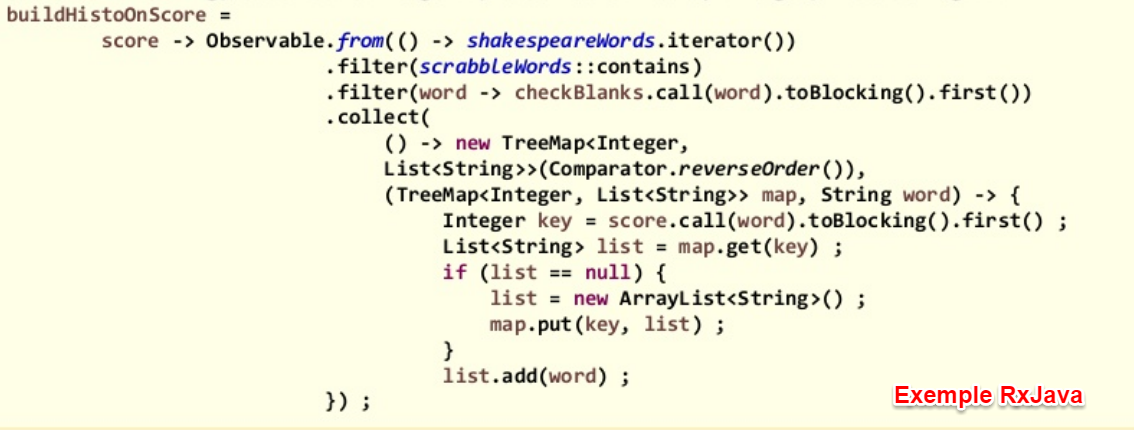
(Personnellement, qu'un conférencier puisse donner en exemple une instruction de 15 lignes, je trouve cela aberrant...)
Au niveau des performances, Streams est un peu moins bon que GS Collections sans le parallélisme, et RxJava est à la ramasse. Avec la parallélisation, dans ce cas, Streams met presque 4 fois moins de temps que GS Collections
GS Collections utilise plus de mémoire que les deux autres.
En conclusion, une présentation pour laquelle j'ai un avis très mitigé, j'ai pu découvrir les API de traitement de données et leurs performances, mais j'ai trouvé le format de la conférence complètement inapproprié. Les supports des conférences données par José Paumard étant disponibles sur son compte Slideshare, je ne suis pas près de préférer de nouveau une de ses présentations à une autre.
Sortez couverts avec Hystrix - Thomas Recloux (indépendant) - 30 minutes
Je connaissais déjà Thomas Recloux via ses participations au Chti' Jug dont il est un des créateurs, et j'aime bien ses présentations qui vont souvent au but via des exemples clairs en live-coding. Sa présentation suivait sur Hystrix suivait toujours se format et était donc très plaisante.
Hystrix est une librairie créée par Netflix permettant la tolérance de fautes et de latences via l'isolation des points d'accès aux systèmes, services et librairies distants.
Pour cela, Netflix s'est basé sur les préconisations remontées dans le livre "Release IT ! Design and deploy production-ready software" par Michael T. Nygard :
Les appels distants doivent être exécutés dans un pool de threads dédiés. Par défaut, le nombre de threads par pool est de 10 dans Hystrix.
En cas d'erreur, une méthode alternative doit pouvoir être appelée.
Un timeout doit être appliqué à chaque appel. Par défaut à 1 seconde dans Hystrix.
Après plusieurs appels, le circuit doit être coupé. Par défaut, Hystrix coupe le circuit après que 50% des appels aient été en échecs sur une période de 10 secondes, avec un minimum de 20 appels les dernières 20 secondes.
Mais comment cela fonctionne ?
Et bien c'est tout simple, lorsque vous allez vouloir exécuter un appel vers votre service/application distant, vous allez créer une commande Hystrix représentée par une classe étendant la classe HystrixCommand , et en lui définissant le groupe (pool de thread) auquel cette commande appartient.
Une fois c'est classe étendue, il ne vous reste plus qu'à déplacer l'appel à votre service dans la méthode run().
Pour lancer un appel, vous devrez désormais instancier votre commande Hystrix, puis exécuter la méthode execute() de cette instance.
Si vous le voulez, vous pouvez même effectuer vos appels de manière asynchrone, puisque Hystrix utilise RxJava en interne.
Thomas a ensuite procédé à une démonstration de sa simplicité, via l'écriture en TDD d'appels à un service, en simulant les timeouts et échecs possibles.
Ce "tools in actions" m'a vraiment donné envie de regarder plus en profondeur Hystrix, et je vous ferais donc sûrement un retour sur expérience de cet outil que je vais tester dans un de mes projets extra-professionnels.
Un Jenkins amélioré avec Docker, Mesos et Marathon - Jean-Louis Rigaud (Xebia) - 30 minutes
Pour ceux qui ne connaissent pas, Jenkins est au départ un serveur d'intégration continue complètement Open-Source. La grande force de cet outil est son extensibilité qui peut faire de lui plus qu'un simple serveur permettant d'automatiquement récupérer le code et le compiler, et ce notamment grâce aux 1200 et quelques plugins existants.
Mais cette flexibilité peut avoir ses défauts et il n'est pas rare de voir des serveurs Jenkins encombrés par des plugins qui ne seront utilisés que par quelques projets. Et c'est quelque chose que l'on voit assez régulièrement, une multitude de projets sur un même serveur maître Jenkins, avec des compilations qui se croisent, se bloquent et éventuellement font planter l'esclave ou le maître compilant, par manque de ressources .
Ce sont ces problèmes auxquels Jean-Louis Rigaud à tenté de répondre en implémentant une variante de la solution utilisée par EBay.
Le principe de cette solution est simple, les ressources utilisées par Jenkins doivent être virtualisées et managées par un gestionnaire de clusters permettant ainsi l'utilisation optimale de ces ressources et éventuellement le redimensionnement et la duplication de ces dernières.
L'implémentation est beaucoup plus complexe et je ne rentrerais pas dans les détails, vu que je découvrais Mesos durant cette présentation et que, bien que je le connaisse, je n'ai jamais eu l'occasion d'utiliser Docker (outil permettant la création de containers applicatifs).
Sachez juste que Mesos, en tant que gestionnaire de clusters, permettait via le "framework" (sorte de plugin pour Mesos) Marathon, de générer des instances maîtres de Jenkins. Via le framework "Jenkins Scheduler", ces instances maîtres vont ensuite pouvoir créer de nouvelles instances esclaves quand nécessaire via l’installation d’images Docker.
Une solution intéressante pour des problèmes que vous n’êtes pas près de rencontrer si vous êtes une startup.
Utilisation de SparkSQL pour analyser vos données Cassandra en Java, Scala et Python - Alexander Dejanovski et Maxence Lecointe (Chronopost) - 30 minutes
Alors je dois vous avouer que je n’ai que très peu eu l’occasion de mettre les mains sur Cassandra et encore moins Spark mais le NoSQL et les solutions Big Data comme Hadoop et plus récemment Spark, sont des sujets auxquels je porte un grand intérêt. Maintenant, je n’ai malheureusement jamais eu l’occasion de pousser ces sujets très loin et j’étais très curieux de voir ce qu’on pouvait faire de ces deux technologies dans un même environnement.
Ce Tools-in-Action commença donc par une présentation rapide de la base NoSQL Cassandra et de Spark.
Pour ceux qui ne connaissent pas, Cassandra est une base NoSQL distribuée qui dispose d’un langage de requêtage (le CQL) qui ressemble beaucoup au SQL mais qui ne permet ni les insertions par requête, ni les group by ou jointures.
Spark, quant à elle, est une solution de traitement de données grâce à du Map/Reduce en mémoire. Spark, paraît-il, serait 10 à 100 fois plus rapide qu’Hadoop.
SparkSQL est quant à lui un module de Spark permettant justement l’exécution d’insertions par requêtes, de jointures et de group by dans les langages Java, Scala et python.
La présentation était très intéressante, mais beaucoup d’éléments et mécanismes apparemment propres à Cassandra et Spark m’étaient complètement inconnus et la présentation ne m’a du coup, pas vraiment parlée.
J’ai quand même retenu que, si vous voulez implémenter des solutions Spark avec du Cassandra, il est fortement conseillé d’utiliser le langage Scala, pour lesquels les connecteurs sont bien plus stables.
Conclusion
Voilà, il est 19h10 et la journée est finie, reste plus qu’à rentrer et à se préparer à la loooongue prochaine journée qui me demandera une fois de plus de faire des choix draconiens.
Ressources
Hands on with Google Compute Engine
Les streams sont parmis nous ! Traitement de données en Java 8
http://fr.slideshare.net/jpaumard/les-streams-sont-parmi-nous
Sortez couverts avec Hystrix
Release It!: Design and Deploy Production-Ready Software
https://github.com/Netflix/Hystrix
Un Jenkins amélioré avec Docker, Mesos et Marathon
eBay's CI Solution with Apache Mesos - Part I
eBay's CI Solution with Apache Mesos - Part II
Utilisation de SparkSQL pour analyser vos données Cassandra en Java, Scala et Python


