Devoxx 2015 - Jour 2
C’est parti pour une deuxième journée !!
Malheureusement, du fait de contraintes personnelles, j’ai raté la keynote qui se tenait la première heure.
Web Components, Polymer and Material Design - Horacio Gonzalez (Citizen Data) - 50 minutes
Je commence donc la journée par une conférence Web. La salle est pleine à craquer, je trouve ça étrange sur le moment qu’une conf’ Web attire autant de personnes.
En rétrospective, c’est compréhensible, c’est sûrement la meilleure session à laquelle j’ai pu assister, si ce n’est au niveau du contenu, au moins au niveau de la présentation.
Si un jour vous avez l’occasion de voir Horacio en conférence, ou lors d’un JUG du Finistère, je vous le conseille vraiment.
Sa présentation, pleine d’humour, nous raconta l’histoire de l’apparition des Web Components, de comment, dans les années 90, on développait des applications lourdes dans lesquelles on créait des Widgets, des éléments de code réutilisables, qu’on assemblait ensuite pour donner notre interface graphique. Qu’avec l’arrivée du web, nous avons du créer des pages html/css au sein desquelles nous copions des blocks entiers de code.
C’est GWT qui au milieu des années 2000, avec l’avènement des applications web à page unique, redonna ensuite la possibilité aux développeurs Web de coder via des Widgets et je dois avouer c’est ce que j’aimais et continue d’aimer dans GWT, la possibilité de coder nos éléments graphiques qui auront leur propre logique graphique et ensuite de les intégrer avec le reste de notre application, pour leur donner un sens métier.
Cette tendance d’avoir une page d’accès unique à votre application web est toujours fortement présente aujourd’hui, mais le développement de ce genre d’application HTML/Css/Js sans la notion de Widget est vraiment douloureux, et c’est pourquoi W3C commença à travailler en 2012 sur la spécification des Web Components.
Mais W3C, on a pu voir un peu comment cela fonctionne avec HTML 5 dont la spécification à mis 10 ans à sortir. Les développeurs et navigateurs n’étant pas près à attendre, des implémentations ou émulations plus ou moins proches des Web Components ont commencer à apparaître, comme AngularJS.
Mais ces implémentations, par des librairies sont toutes différentes et non interropérables : Les directives AngularJS ne fonctionnent qu’avec AngularJS.
Les navigateurs quant à eux ont également plus ou moins commencé à émuler ces composants, avec plus ou moins d’avancement. L’implémentation par Chrome et Opéra est complète via la surcouche Polymer, celle de Firefox partielle, et le reste on en parle pas.
“Mais du coup pas de Web Components sur IE actuellement ?”
Et bien pas exactement puisqu’en 2013, Google présenta Polymer, une surcouche aux Web Components permettant justement l’utilisation de ces derniers sur les navigateurs ne l’implémentant pas. C’est ce qu’on appelle un polyfill.
Désormais, via le simple import du script polymer.js, il vous est donc possible de créer des éléments réutilisables d’une page à l’autre via des éléments html conçus par vous, ou toute autre personne.
Si vous voulez savoir plus en profondeur en quoi consiste un Web Component, je vous conseille fortement de visionner la vidéo de la conférence, qui devrait être disponible sur le site de la Devoxx prochainement.
Personnellement, j’ai tellement aimé la conférence, que j’ai décidé de changer un peu mon planning et d’aller au labs Polymer organisé par Google après manger.
Ressources :
Présentation du GDG Nantes semblable à celle de la Devoxx
Cloud enpoints, Polymer, material design : the Google stack, infinitely scalable, positively beautiful - Martin Görner, Mandy Waite, Ray Tsang (Google), Horacio Gonzalez (Citizen Data) - 3 heures 1 heure 20 minutes
Bon alors petit conseil, si vous allez un jour à la mezzanine du palais des congrès, ne prenez pas votre blouson chaud…
Nous arrivons dans la salle et nous nous installons pendant que Martin Görner commence un peu à présenter l’équipe et le labs. Ce dernier consiste en la création d’un “Cloud endpoint”, API à déployer sur AppEngine, et d’une appli web utilisant le Material Design grâce à Polymer.
La connexion internet est lente, très lente.... Nous sommes du coup obligés de récupérer les environnements de développement sur une clé.
###p
ès>
Bref, après 45 minutes, j’ai enfin un environnement qui fonctionne. Je suis en train de me dire que ça va être la galère pour finir le lab en 2h25… Puis je regarde les slides…
20 minutes après, je ressors du lab en ayant tout ou presque fini,. Après tout, des conf’ viennent de commencer et je vais essayer de me trouver une petit place plutôt que de passer 2 autres heures à rien faire ou a expérimenter des trucs tout seul, ce que je pourrais faire chez moi.
Changing the wheel of a moving car - faire évoluer l’infra sans interruption - Nicolas de Loof - 50 minutes
Ok ! Comme je disais hier, je suis un grand fan de Jenkins dont j’aime beaucoup la philosophie et la direction, d’où ce choix de conférence.
En effet, Nicolas de Loof travaille chez CloudBees, la société fondée entre autre par le créateur d’Hudson/Jenkins Kohsuke Kawaguchi.
J’arrive un peu après le début de la conférence et Nicolas (déguisé en panda o_O) a déjà dû se présenter. Il nous explique que cette conférence va parler de comment CloudBees a mis en place une infrastructure permettant de proposer des solutions Jenkins dans le Cloud, des problèmes rencontrés et autres.
Il commence par nous dire que le Cloud, bien que très puissant, dispose de certaines faiblesses:
Il dispose d’une faible QoS
Les serveurs sont considérés comme du bétail. C’est des bouts de tôles pour les personnes mettant en place les infrastructure Cloud.
CloudBees veut faire du Jenkins As A Service et Jenkins dépend fortement du système de fichiers, pas pratique dans le Cloud.
Mais heureusement, CloudBees a apparemment fait de bons choix au démarrage de leur plate-forme comme isoler les API EC2 (Elastic Cloud Computing, service d’AWS), et activer le remplacement de serveur par leur terminaison plutôt que d’utiliser des outils comme Chef.
Le principe est simple : Vous voulez changer d’OS ? Créez une nouvelle image AMI (Amazon Machine Image) et Terminez votre ancienne instance. La nouvelle instance avec le nouvel OS prendra naturellement sa place.
Un patch de sécurité à installer ? Même principe.
Un serveur un peu lent ? Toujours le même principe.
Cette pratique leur a apparemment été très utile durant l’année 2014, quand plusieurs failles de sécurité importantes ont été “découvertes” comme HeartBleed et ShellShock. Les machines virtuelles de CloudBees étant régulièrement remplacées par des machines mises à jour, ces failles n’ont jamais vraiment été un problème pour elles.
Mais que deviennent les données si on termine et remplace toutes nos machines ?
Et bien dans l’idéal, vous utilisez un système de données distribuées. Au fur et à mesure que vos machines s’éteignent et se rallument, les données sont propagées aux nouvelles machines.
Sinon, il vous faudra utiliser un service comme EBS (Elastic Block Store) d’Amazon, qui vous permettra d’effectuer des instantanés continus de vos données pour les restaurer sur vos nouvelles machines.
Le reste de la conf’ avait pour sujet le remplace de LXC par Docker, et les préconisations de CloudBees en terme de monitoring, ce que je trouve bien moins intéressant mais voici quelques une de ces remarques :
Faites attention aux droits sous Docker, si un utilisateur Docker est root et arrive à sortir du contexte du container Docker, il sera toujours root !
Pour le monitoring, vérifiez l’évolution de vos indicateurs plutôt que si ils sont tous au vert.
N’utilisez pas de Dashboard trop riches. Le but est d’informer la bonne personne pas de les noyer.
Ajustez vos alertes pour n’alerter vos Ops qu’en cas de risque vital, cela augmente l’urgence de vos alertes et diminue leurs volumes. (voir le papier###a href="http://fractio.nl/2014/08/26/cardiac-alarms-and-ops"> http://fractio.nl/2014/08/26/cardiac-alarms-and-ops)
###p
ès>
Ressources
###a href="Slides" class="redactor-linkify-object">https://docs.google.com/a/esen... du lab
Http/2 : A deux c’est mieux! - Jean-François Arcand (Async-io.org)
Depuis 2009 a peu près, je suis de loin l’évolution des Web Sockets, ce protocole permettant ce qu’on appelle des Push Serveur. Traditionnellement, seules les machines clientes peuvent initialiser une communication avec un serveur et les Web Sockets, via un fonctionnement un peu particulier, permettent justement le contraire, de notifier les machines clientes sans que celles-ci initialisent cette communication.
###p
Et les Web Sockets ne se sont que peu démocratisées depuis, et c’est pourquoi des outils comme Atmosphere sont apparus sur la toile, permettant d’utiliser les Web Sockets facilement, et de les émuler quand celles-ci ne sont pas supportées.
Jean-François Arcand est justement le créateur d’Atmosphere, et il est là pour nous expliquer un peu ce que c’est qu’Http/2.
Http/2 a été imaginé pour régler les problèmes d’Http, principalement le fait que les headers sont beaucoup trop souvent dupliqués et renvoyés, résultant en une consommation de la bande passante souvent peu utile.
Http/2 s’inspire très fortement du protocole SPDY de Google et n’apporte pas de changements à la sémantique d’Http. Du coup, l’utilisation de ce protocole est pratiquement invisible pour l’utilisateur, puisque celui-ci se connectera toujours à des adresses du type “http://”.
Les 4 éléments principaux d’Http/2 sont :
Le multiplexing
Le navigateur ouvre une seule et unique connexion avec le serveur et peut envoyer plusieurs requêtes, aussi appelées streams. Ces streams sont asynchronisables et priorisables, contrairement à Http où la priorisation des requêtes était décidées par les navigateurs et où le serveur subissait, dans Http/2, le serveur peut décider de cette priorisation et les priorisations décidées par les navigateurs sont justes des propositions.
Compression de Headers (HPACK)
Il est optionellement possible de compresser vos headers et si j’ai bien compris, les headers eux même sont optionnels.
Chiffrement
Grandement influencé par les révélation de Snowden sur la NSA, il a été décidé que toutes les communications Http/2 seront chiffrées. Du coup, adieu Https !
Push
Mais voilà la principale raison de l’intérêt que je porte, en tant que développeur, à Http/2.
Http/2 supportera nativement le push !
Mais quel est l’état actuel d’Http/2 ?
Et bien à l’heure actuelle, très peu de serveur implémentent ce protocole, dont les principaux sont Jetty et Undertow (moteur web de JBoss).
Donc à l’heure actuelle, la seule solution que vous avez pour utiliser Http/2 est d’utiliser l’API un des rares serveurs l’implémentant mais d’ici quelques mois, Servlet 4.0 devrait sortir ainsi qu’Atmosphere 3.0 qui doit sortir en Septembre 2015 et qui devrait vous permettre d’abstraire votre utilisation d’Http/2 pour retomber sur des solutions de recours (Http/1.1 et Web Sockets) quand cette utilisation n’est pas possible.
Java EE 7 Batch Processing in the Real World- Roberto Cortez (Indépendant), David Delabassee (Oracle) - 50 minutes
Les batchs, c’est un peu la galère. On a tous nos différentes implémentations de ceux-ci, via des exécutables java, des scripts pythons ou shell, et je ne parle même pas des “schedulers”, ces outils supposés lancer et monitorer nos batches…
C’est pourquoi un nouveau standard Java, qui pourrait éventuellement nous mener à tendre vers une implémentation unique (c’est beau de rêver), m’intéressait fortement.
D’après Roberto et David, un batch se définit comme : “Un groupe d’enregistrements traités comme une unité, généralement sans entrées utilisateur.”
Ces batchs nous servent à nous focaliser sur une tâche de façon répétitive et efficiente, aux moments opportuns pour utiliser des ressources inutilisées. Essayez de rapprochez ça de vos courses :
Vous irez faire vos courses quand vous aurez un besoin et que vous n’aurez rien de plus important à faire et généralement, vous n’irez pas acheter un seul article mais un groupe d’articles.
L’API Java, disponible depuis Java 7 et créée en s’inspirant fortement de Spring Batch, tente donc de permettre cela. Les principales fonctionnalités proposées par cette API sont :
La parallélisation ou l’exécution séquentielle des étapes du batch.
La création de points de contrôle.
La gestion du workflow.
La possibilité d’arrêter et de redémarrer un traitement.
La gestion d’exception.
Pour créer votre batch, vous allez devoir définir dans un fichier xml des étapes à votre batch qui contiendront des sous-étapes pour lesquelles vous pourrez définir des traitements d’exception.
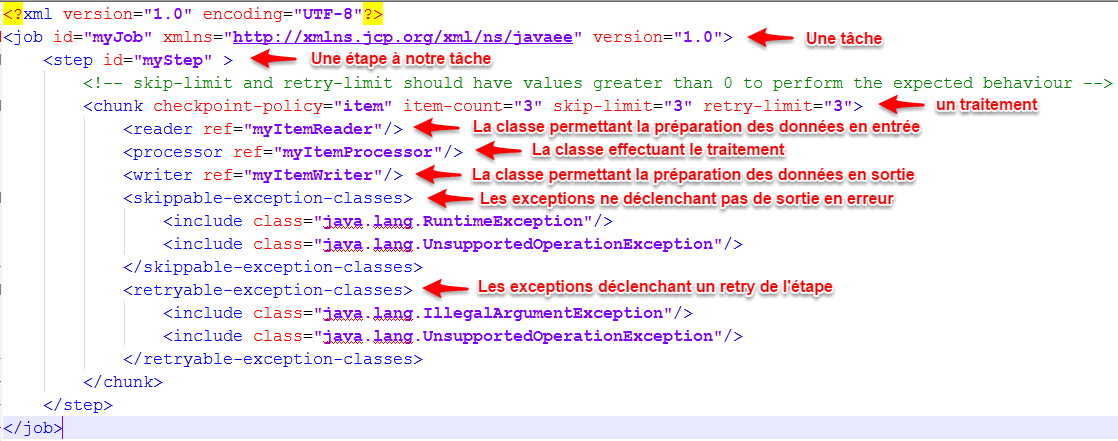
Un exemple de batch.
Au final, je n’ai pas été particulièrement emballé par cette API, elle propose effectivement des moyens simples de définir un batch en tant qu’ensemble d’étapes et sous-étapes à exécuter de façon séquentielle ou parallélisée, avec des “fallbacks” possibles, mais je trouve malheureusement la configuration pas assez dynamique.
On ne peut par exemple pas spécifier dans la configuration un temps d’attente avant de relancer l’exécution d’un batch, ou encore dynamiser la parallélisation pour laquelle nous sommes obligés de définir manuellement dans la configuration sur quels ensembles de valeurs lancer les batchs à paralléliser. Pas tip-top donc…
Maintenant, je ne connais pas Spring Batch et il parait que, dans sa dernière version, cette librairie implémente l’API java en lui rajoutant un certain nombre de fonctionnalités. Peut-être que Spring Bath répondra donc à mes attentes. A creuser…
Ressources
###a href="http://fr.slideshare.net/radcortez/con2818-java-ee-7-batch-processing-in-the-real-world">Lien de sa présentation semblable à la JavaOne 2014
Construire des application Big Data avec Docker et Mesos- Sam Bessalah (Indépendant) - 50 minutes
Comme je vous disais, je suis allé voir une conférence hier sur l’utilisation de Mesos et Docker pour avoir une architecture Jenkins scalable. Cela m’a rendu assez curieux sur comment Mesos pouvait être utilisé dans des problématiques un peu plus “standards”, et le Big Data, au même titre que les problématiques DevOps, est également un sujet auquel je m’intéresse de près.
Et autant vous dire que Sam, il maîtrise son sujet. Sans slides pendant une bonne partie de la présentation (problème réseau), il a tenté de nous présenté une architecture distribuée facilement scalable et “resource-effective” avec Docker et Mesos.
Il commence par nous expliquer le vrai problème du Big Data, c’est la scalabilité de votre système.
Si vous utilisez un cluster de serveur partitionnés de façon statiques, vous allez vous retrouver avec une partie de vos serveurs hébergeant vos machines Hadoop, une autre partie vos applications d’intégration continue, une autre encore vos bases de données, etc…
Mais vos ressources ne sont pas utilisées de manière si statique, Hadoop et vos machines d’intégration continue seront plus en demande la nuit, vos serveurs Web et bases de données le jour, etc..
Du coup, vous vous retrouverez avec des ressources régulièrement non utilisées, qui pourraient être réparties sur vos applications en besoin.
C’est à ce problème que Sam Bessalah tente d’apporter une solution via un gestionnaire de clusters Mesos et des containers Docker.
Mesos, en effet, permet de rajouter une couche d’indirection à vos demandes de ressource. Plutôt que de contacter un cluster spécifique pour votre application web ou votre base de données distribuée, vous allez accéder à une unique adresse mesos qui va ensuite vous rediriger vers la machine qu’il juge pertinente.
Si Mesos observe une augmentation de la charge, il va également pouvoir des ressources aux machines non utilisées et, si besoin est, Mesos va alors déployer une nouvelle instance de votre application, base de données ou autre en rajoutant, via son framework Marathon, un container Docker à une ou des machines dont les ressources ne sont pas ou peu utilisées.
Voilà grossièrement la solution apportée par Sam Bessalah, bien sûr, la présentation était bien, bien plus technique que ça mais i le sujet vous intéresse, je vous laisse lire la présentation qu’à pu faire Sam à la Devoxx Belgium
Ressources
Présentation de la Devoxx Belgium 2014
Jeu de rôle en ligne massivement multijoueur avec Firebase- Alexis Moussine-Pouchkine (Google), Thomas Guerin (Xebia) - 30 minutes
J’avais déjà vaguement entendu parler de Firebase, cette base de données avec un système de propagation quasi-instantanné des modifications de données mais je n’ai jamais vraiment eu le temps de m’y intéresser.
D’après Alexis et Thomas, la donnée perd de la valeur au fur et à mesure qu’elle vieillit, et “quelques pouillèmes” de secondes gagnées dans le monde de la finance peuvent représenter des centaines de milliers d’euros.
C’est pourquoi il est important dans le monde actuel de synchroniser nos données en temps réel. Mais ce mode de synchronisation pose de gros problèmes de transport et de persistence.
Firebase essaie donc de répondre à ces problématiques en transmettant immédiatement à l’ensemble de ses clients les nouvelles données lorsque celle-ci sont mises à jour.
Pour faire cela, un client va devoir s’inscrire à des évènements sur un noeud de Firebase, un noeud correspondant à un élément du document JSON que Firebase utilise en tant que “base de données”, et y rajouter une logique de traitement via une fonction qui sera appelée de manière asynchrone quand le document sera mis à jour par un tiers.
Bien sûr, cela apporte certaines limitations, la profondeur maximum des noeuds est de 32 et vous êtes assez limités dans la complexité et volumétrie de votre base de donnée.
Mais en contrepartie, Firebase est complètement gratuit ! Votre base de données est effectivement hébergée sur le Cloud gratuitement et vous y accédez via une URL finissant en “firebaseio.com” .
Dans leur démonstration, Thomas et Alexis nous montraient comment ils avaient pu créer un jeu dont l’objectif est de prendre le plus de gares possibles sur une carte du monde. Ils nous expliquaient que les gares étaient récupérées depuis des données ouvertes et stockées dans un noeud de Firebase et que les utilisateurs authentifiés via une authentification Google simple et facilement intégrable, étaient stockés dans un noeud différent.
Lorsque l’utilisateur se déplaçait sur la carte, l’application,via une librairie nommé GeoFire, encapsulait ensuite leur noeud “Gares” vers lequel GeoFire pouvait effectuer des requêtes récupérant les gares présentes aux coordonnées visualisées par l’utilisateur.
Lorsqu’un utilisateur cliquait sur une gare, cette gare changeait de propriétaire, et cette information était propagée directement aux autres clients, permettant ainsi une application temps-réel.
Conclusion
Voilà c’est la fin de cette journée, enfin presque… Il me reste encore les “Birds of a Feather” où se rencontrent les communautés de passionnés sur une technologie ou tendance.
J’ai personnellement participé aux BOF Jenkins et Maven où j’ai pu découvrir pour la première fois les personnes participant au développement de ces deux produits.
Je vous laisse donc sur ces quelques mots en rapport aux BOFs :
Je ferais “prochainement” un retour sur la nouvelle notion de Workflow de Jenkins en essayant de vous présenter à quel point cette nouvelle orientation de Jenkins que j’ai découvert l’année dernière et qui est sortie en version 1.0 en début d’année est géniale.
La communauté Maven est à la recherche de commiteurs. Il y a énormément de choses dans le pipe et nous disposons depuis Juillet 2014 d’un Parisien au Comité de Gestion du projet Maven : Hervé Boutémy, qui apparemment n’est pas du tout contre parler de Maven autour d’une bière. ( hboutemy@apache.org)


