Devoxx 2015 - Jour 3

Et voilà, c’est déjà le dernier jour, après ce soir, faudra attendre les prochaines éditions et bien sûr, les vidéos des conférences que j’ai pu louper..
Mais bon, il me reste encore quelques conf’ à voir qui devraient être bien intéressantes !
La keynote
Je ne parlerais que peu de la Keynote, les 4 conférenciers avaient pour mission de se projeter dans l’avenir sur un horizon de 20 ans. Chacun avait son domaine de prédilection, robotique, applicatif décentralisé, hébergement et pour finir Java.
La robotique
Pierre-Yves Oudeyer, directeur de recherche à l’INRIA, avait décidé d’orienter son discours sur l’apprentissage des robots, estimant que c’est la robotique évoluerait via l’amélioration constante des algorithmes d’apprentissage, afin de tendre vers un développement cognitif semblable à celui d’un enfant.
Il nous expliqua qu’à l’heure actuelle ce développement se fait à l’aide d’un “algorithme de curiosité”, aussi appelé : Intelligent Adaptive Curiosity.
Le principe de cet algorithme est relativement simple :
Quand le robot effectue une action, il va faire une prédiction de la réaction, la conséquence de son action.
###p
ès>
Pour voir un peu le système en pratique, je vous invite à visualiser l’expérience “Playground” :
###a href="https://www.youtube.com/watch?v=tbEYnTzMDgs"> https://www.youtube.com/watch?v=tbEYnTzMDgs
La singularité de décentralisation
Stephan Tual, Chief Commercial Officer d’Ethereum, commence par nous expliquer qu’avec l’arrivée d’Internet, tout le monde pensait que l’information allait subir une énorme décentralisation.
Or, bien qu’à l’origine, le modèle IP avait été imaginé pour fonctionner de pair à pair, il s’avère que nous fonctionnons actuellement dans un modèle serveur/client et que cette décentralisation, non seulement ne s’est jamais faite, mais son inverse même s’est produit via la montée en puissances d’oligopolistiques (Google, Facebook, Netflix, Über et autres), qui nous font tendre vers l’utilisation d’un Internet centralisé selon notre utilisation.
Stephan continue par nous dire que sa société, Ethereum, essaie justement d’aller en contresens de cette tendance, en proposant un service d’hébergement pair à pair, le rendant ainsi décentralisé, que Stephan espère deviendra le standard d’ici 20 ans.
La fin de la gestion serveur : l’hébergement en tant que commodité
Quentin Adam, CEO de Clever Cloud, nous prédit que l’hébergement deviendra une commodité d’ici 20 ans.
Il nous fait pendant 20 minutes une magnifique comparaison avec deux industries existantes, celle du bâtiment et celle de l’énergie (plus spécifiquement de l’électricité).
Il nous explique que jusqu’à il y a quelques années, l’informatique fonctionnait de la même manière que le secteur du bâtiment. Nous avions d’ailleurs souvent dans nos projets les notions de maîtrise d’ouvrage et de maîtrise d’oeuvre, venant tout droit de ce secteur.
Maintenant, l’informatique est une industrie de service est financièrement liquide, les services sont auto-suffisants et s’améliorent continuellement. L’industrie informatique, nous dit il, est actuellement dans sa révolution industrielle.
Le problème, c’est que nous fonctionnons actuellement avec des serveurs que nous sommes obligés de maintenir, sur lesquels sont effectués des backups et pour lesquels nous devons nous battre corps et âme pour éviter l’interruption de service.
Tout ceci n’est vraiment pas industriel et pour lui, l’hébergement doit devenir complètement pluggable.
Pluggable ? Mais qu’est-ce ? Et bien quand vous branchez vos appareils électriques sur une prise de courant, est-ce que vous vous posez ne serait-ce qu’une seule fois la question si cela va fonctionner ?
Je vais partir du principe que vous n’êtes pas complètement paranoïaque et que non, vous vous ne posez jamais ce genre de question. E bien pour Quentin, c’est cela le pluggable et même titre que l’industrie électrique, il espère que dans 20 ans, l’hébergement aura évolué jusqu’à être complètement pluggable.
Java : Les 20 prochaines années
Le titre est trompeur et certains estimeront que Brian Goetz, Architecte du langage Java chez Oracle, aura fait un hors-sujet dans cette conférence.
Mais bien que n’étant pas une projection de ce que deviendra Java dans 20 ans, Brian nous délivre quand même quelques informations intéressantes sur les prochaines évolutions de Java.
Il nous parle également beaucoup de comment Java à évoluer jusqu’à sa version actuelle et pourquoi Java 9 s’est focalisé sur la modularisation du langage mais ce qui m’a vraiment intéressé, fut quand il parla du projet Valhalla.
Le projet Valhalla essaie d’apporter un nouveau type d’objet à l’environnement Java : les “Value Types Specialized Generics”.
Un mot un peu barbare oui, mais le principe est simple : Codé comme une classe, se comporte comme un int.
Le comportement dont il parle se situe au niveau de l’allocation mémoire, le principe est que la réservation mémoire pour ces objets se ferait au niveau du “Heap” et non de la “Stack”, permettant potentiellement de faire diminuer grandement la consommation mémoire de la JVM.
DevOps with JavaEE - Arun Gupta (Red Hat) - 50 minutes
Comme vous devez le savoir désormais, je suis très intéressé par les pratiques DevOps. Mais qu’est-ce que DevOps ? Et bien entendez vous régulièrement ou dites vous régulièrement : “Ca marche pas en recette ? Pourtant ça marchait bien sur ma machine...” ?
Si oui, commencez à regarder du côté des méthodes DevOps. Les méthodes DevOps ont en effet pour but de réunir les métiers de Développeur et d’Intégrateurs (Operations en anglais), d’où le mot DevOps.
D’après Arun, les pratiques DevOps permettraient en effet de livrer votre code jusqu’à 30 fois plus vite et d’éviter 50% des problèmes d’intégration qu’on pourrait avoir sans ces méthodes.
Arun continue par nous expliquer que pour mettre en places ces pratiques, il faut passer par les 5 Cs:
Collaboration
Dès le début du projet, les Développeurs et les Intégrateurs doivent travailler ensemble. Le job d’un intégrateur n’est pas de garder le site stable et rapide, mais de permettre les affaires. Le boulot du développeur est exactement le même et il devrait donc être normal que les deux travaillent ensemble.
Culture
La partie la plus difficile à implémenter puisqu’elle demande le respect de l’expertise, des opinions et des responsabilités de chacun, qu’il soit développeur ou intégrateur.
Il faut vraiment dans les pratiques DevOps qu’il y ait une culture de la transparence, amenée par le développement de la confiance en chacune des parties/personnes.
Cela ne veut absolument pas dire qu’il faut ignorer les erreurs et il faut au contraire amplifier les boucles de feedback (dans un projet Scrum, les intégrateurs doivent participer au Scrum Meeting par exemple).
Tout Coder
Le principe est simple, ne jamais envoyer un humain faire le boulot d’une machine et tout est sujet à automatisation
Consistance
Il vaut mieux automatiser plutôt que documenter puisque cela donne de la répétabilité. Les déploiements doivent donc être faits à la poussée d’un bouton et la gestion d’environnements (de dèv et de recette) relativement simple.
Pour cela, il existe un grand nombre de technologies utilisables dont voici quelques exemples :
les Paas (AWS, GCE, OpenShift) pour le Cloud computing
Virtual Box et Vagrant pour la virtualisation
Docker et Rocket pour la containerisation
JBoss EAP et Tomcat pour les serveurs applicatifs
Puppet, Chef, Ansible et Salt pour la configuration
Docker Compose et Kubernetes pour l’orchestration
etc …
Il est également recommandé de construire des dashboard, ce qui permet d’augmenter la transparence de votre architecture ( http://stackexchange.com/performance)
Déploiement Continu
Pour mettre en place du déploiement continu, vous commencerez généralement par faire de l’intégration continue. La différence entre les deux est que l’intégration continue ne consiste grossièrement qu’en la compilation de vos projets, alors que le déploiement continu consiste également à déployer de façon automatique et régulière vos applications (Si vous êtes intéressés par les pratiques de déploiement continu, je vous invite à lire le livre : Continuous Delivery).
Le déploiement continu permet de voir rapidement les erreurs et de les remonter avant qu’elles ne soient visibles à des moments critiques. Pour que le déploiement continu soit efficace, il est également important de bien monitorer vos applications. C’est ainsi que vous détecterez des comportement anormaux au niveau de l’utilisation que font vos applications de vos ressources.
Writing Java Secure Code - Azzeddine RAMRAMI (Pierre & Vacances) - 3 heures (2 heures)
Alors OK, Pierre et Vacances pour un informaticien, ça vend pas du rêve, mais Azzeddine RAMRAMI par contre, il maîtrise vraiment son sujet.
Je ne suis resté que 2 heure à son Lab car je voulais vraiment assister à la présentation de Critéo, n’y voyez donc pas une mauvaise opinion de son lab qui était le meilleur auquel j’ai pu assister durant ces 3 jours de Devoxx.
Azzeddine RAMRAMI commence par nous dire qu’il s’est basé sur le contenu de la certification CERT Oracle Secure Coding Standard for Java qu’il fait passer, en allégeant grandement le contenu puisque ces certifications sont sensées se dérouler sur 3 jours.
Cette certification est en effet composée d’un grand nombre de règles de sécurité à connaître (plus de 400 je crois bien mais je n’ai pas réussi à confirmer le nombre). Celles-ci sont décomposées en plusieurs domaines de sécurité


Bien sûr, il n’est pas nécessaire quand vous développez une applications sécurisée de suivre à la lettre et de tester l’ensemble de ces règles : Cela vous prendrait beaucoup trop de temps pour des règles qui ne s’appliquent pas toujours dans votre contexte !!
Vous allez donc devoir passer en début de projet par une étape de modélisation des menaces pour déterminer quelles sont les règles fondamentales à suivre dans le cadre de votre application.
Sachez cela cependant, peu importe le nombre de règles de sécurité implémentées, le maillon faible reste et restera l’Humain.
En effet, 70% des attaques viendraient apparemment de l’intérieur, par un acte de malveillance ou non. Cela peut-être un employé qui laisse sa session ouverte, donnant la possibilité à des personnes malveillantes de récupérer des informations confidentielles (ou pire), un employé qui vole des informations pour les diffuser (eg : Snowden), un ancien ou actuel administrateur mécontent, etc…
Mais il très difficile dans notre métier d’informaticien de se protéger de ce genre d’attaques et nous allons donc maintenant nous concentrer sur les parties où nous avons réellement un pouvoir d’action : l’applicatif.
80% des attaques applicatives, nous dit Azzeddine, proviennent d’une mauvaise implémentation des règles de sécurité du domaine 00, contenant l’ensemble de la validation des données en entrée, les plus connues étant les injections de code SQL ou Javascript dans une partie mal protégée de votre site Web où ce code sera interprété et exécuté. C’est pourquoi le reste du lab portera sur ce domaine en présentant des exemples de code non sécurisé, et leur sécurisation.
Injections SQL
Commençons donc par la sécurisation des injections SQL en Java. Elle est assez simple puisqu’elle consiste à utiliser des objets PrepareStatement pour créer vos requêtes SQL dynamiques plutôt que de concaténer vos variables dans vos chaînes de caractères consistant votre requête :
Exemple Injection SQL (IDS00-J)
Injection XML
Les documents XML sont très régulièrement utilisés dans le monde applicatif, du fait de leur grande simplicité et flexibilité, mais ils sont également susceptibles à un grand nombre de vulnérabilités, dont l’injection XML.
Comme l’injection SQL, l’injection XML consiste également à insérer des données à des endroits non voulus. Par exemple, dans un contexte e-commerce où le client pourrait renseigner les quantités qu’il veut d’un article, si la communication client/serveur se fait via la transmission de documents XML et que vous ne gérez pas correctement la validation des données en entrée, il est possible que ce genre de cas arrive :
Par exemple si vous vous communiquez le genre de document suivant :
<article>Ford Fiesta</article>
<prix>7500.00</prix>
<quantite>1</quantite>
et que le client rentre dans la quantité voulue :
1</quantite><prix>1.0</prix><quantite>200</quantite>
Il est alors possible que le client puisse commander 200 Ford Fiesta pour le prix d’un euro, ce qui pourrait être un poil grave.
Exemple Injection XML (IDS16-J-C)
Quelques autres exemples ont suivis avant que je quitte la salle pour assister à ma tout dernière conférence. Heureusement, j’ai pu récupérer l’ensemble du contenu du lab’.
###h1
Pour la dernière conférence, j’ai choisi d’aller voir la présentation de Critéo sur leur infrastructure, qui avait déjà été plus ou moins présentée à un meetup du Paris Datageek auquel je n’avais pas pu assister.
Comme vous devez maintenant le savoir, je suis en effet très intéressé par les solutions Big Data et Critéo est soumis par son métier à de grosses contraintes de performance sur de gros volumes de données.
En effet, Critéo est une boîte faisant du rachat d’espaces publicitaires sur le net, au sein desquels ils affichent les publicités de leurs clients qui les paient au clic.
Une publicité affichée et non cliquée est donc de l’argent perdu pour eux et il est ainsi nécessaire pour l’entreprise de pouvoir prédire le plus efficacement possible quelle publicité afficher à quel endroit pour que la prédiction de clic soit la plus haute. Tout leur business model est basé sur cette prédiction du clic.
Pour cela, ils utilisent plusieurs algorithmes de Machine Learning effectuant de la régression logistique distribuée sur la base des timelines utilisateurs qu’ils ont pu récupérer ou enregistrer.
La régression logistique leur permet en effet d’utiliser des algorithmes d’apprentissage rapides (même si moins performants) tels la descente du gradient dont le principe est de trouver de façon itérative la valeur optimale du paramétrage en itérant systématiquement dans le sens du minimum local.
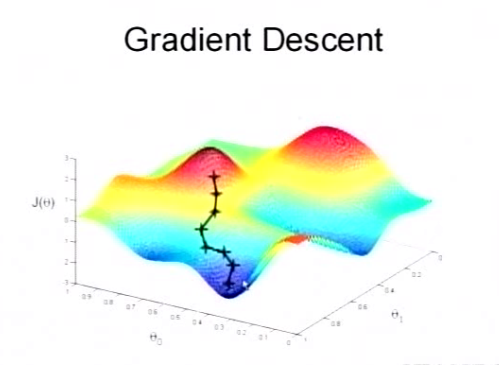
En volume, cela donne 30 millions de clics sur 570 millions de “displays”, correspondant à environ 7 To de données lorsque compressé et 190 millions de lignes après normalisation (comprenez réduction du bruit, sélection des données “modèles”, etc…).
Ces données doivent être traitées le plus rapidement possible lorsqu’un nouvel espace d’affichage est mis en vente, pour éviter l’achat d’un espace publicitaire ayant une faible probabilité de générer un clic.
Pour cela, Critéo dispose de 7 Datacenters contenant près de 12 000 serveurs pouvant traiter les millions de requêtes par seconde.
L’ensemble des étapes de pré-traitement de ces informations sont codées en C# et leurs algorithmes sont eux calculés sur Hadoop. Malheureusement Hadoop est très (très) fortement orienté Java (comme la plupart des solutions Map/Reduce) et donc Critéo est obligé de passer parHadoop Streaming qui leur permet d’exécuter des jobs Map/Reduce provenant d’un code compilé via Mono.
Les slides de cette dernière présentation étaient très informatifs et dès que la présentation sort et/ou que je retrouve ces slides, je les ajouterai à cet article.
Les stands
En dernier point, j’aimerais passer très rapidement sur deux stands présents à la Devoxx qui, je pense, méritent au moins un second regard plus approfondi.
La première est en fait une boîte qui s’appelle JFrog. JFrog propose deux solutions liées à la gestion de livrables :
Artifactory
Artifactory est une alternative à Nexus, le gestionnaire de dépendances de Sonatype. Je connais plutôt bien Nexus ainsi que ses problèmes d’optimisation et autre bogues, et il me parait intéressant de connaître une solution alternative, bien que cette dernière semble assez limitée dans sa version gratuite.
Bintray
Bintray est une solution de distribution automatisée de vos applications qui dispose d’entrées et de sorties via des API Rest et une interface Web.
Ayant travaillé auparavant dans une société éditrice de progiciels, c’est typiquement le genre de solution que je rêvais de mettre en place avec des solutions de déploiement de produits automatiques en fonction des licences.
La deuxième solution que j’aimerais présenter est ###a href="http://streamdata.io/">streamdata.io.
Streamdata.io est une sorte de proxy entre vos applications qui va cacher (stocker en mémoire et pas recouvrir d’un drap hein !) les données que vous transmettez d’une application à une autre.
Le grand avantage de streamdata.io est que non seulement ces données sont cachées, mais lors du renvoi à votre application destinataires, seules les données modifiées sont renvoyées à cette application destinataire.
A l’heure actuelle (et je ne pense pas que ce soit prévu dans la roadmap), vous êtes obligés de passer par leur serveurs, réduisant grandement l’intérêt je trouve, mais peut être qu’une solution sera distribuée plus tard pour l’installer sur vos serveurs locaux. A suivre…
Conclusion
Voilà, la Devoxx est finie, j’ai pu y voir pas mal de choses intéressantes, même si j’ai également raté par manque de places une ou deux conf’ et que mon choix aurait pu être meilleure pour d’autres.
Mais voilà, je sais à quoi m’attendre désormais et j’espère que j’aurais un peu plus l’occasion lors de mes prochaines conf’ de parler avec les acteurs de l’informatique française ou européenne.
Si vous avez des remarques, conseils et autres sur ces articles ou ce qu’ils entouraient, n’hésitez surtout pas puisque moi-même je les trouve bien trop difficiles à digérer. Plus d’images et de formatage ne seraient pas un mal je pense et j’espère trouver le temps dans les prochaines semaines de les retravailler un peu, histoire de potentiellement trouver une trame de présentation à mes articles qui les rendraient un peu plus lisibles.


